Votre boutique WooCommerce affiche un score PageSpeed de 90+. Les images sont compressées, le thème est léger, les plugins sont raisonnables. Et pourtant, des clients vous signalent que le site rame. Le checkout prend 4 secondes. Le panier met du temps à se mettre à jour. L’admin devient pénible aux heures de pointe.
Le réflexe habituel : changer de thème, supprimer des plugins, installer un énième plugin de cache. Sauf que le problème n’est presque jamais là. Sur les boutiques WooCommerce que j’audite, quand la lenteur touche le panier, le checkout et l’espace client, c’est le stack serveur qui pose problème. Pas le front-end.
Voici pourquoi, et ce qu’il faut vérifier.
Le cache ne protège pas votre checkout
Cache de page, CDN, optimisation des assets statiques : tout ça aide pour les pages catalogue consultées par des visiteurs anonymes. Sur ce type de pages, le cache réduit les temps de chargement de 60 à 80 % (WP Rocket, Cloudways).
Mais WooCommerce ne fonctionne pas comme un blog. Dès qu’un visiteur se connecte, ajoute un produit au panier ou arrive au checkout, le cache de page est contourné. Chaque action génère une requête PHP directe vers la base de données : mise à jour du panier, calcul des frais de port, vérification du stock. WP Rocket le dit clairement dans sa documentation : les pages dynamiques (panier, checkout, compte client) ne peuvent pas exploiter le full-page cache.
Si votre stack serveur n’est pas dimensionné pour gérer ces requêtes dynamiques simultanées, le Time to First Byte (TTFB) grimpe là où ça compte le plus pour votre chiffre d’affaires. Soldes, Black Friday, lancement produit : c’est précisément quand le serveur est le plus sollicité que la conversion se joue.
Et le score PageSpeed Insights ne vous alertera pas. Il teste une page statique, souvent la home, en conditions de laboratoire. Le poids des pages en lui-même n’est pas le bon indicateur, c’est ce qui les rend lourdes qui compte. Le score PageSpeed peut masquer des problèmes bien plus profonds, comme un maillage interne défaillant ou un serveur sous-dimensionné.
NGINX + PHP-FPM : la base d’un stack e-commerce
Apache est le serveur web par défaut de la majorité des hébergements WooCommerce. Il fonctionne. Mais il a un défaut structurel pour le e-commerce : chaque connexion simultanée consomme un processus dédié avec sa propre allocation mémoire.
Quand 200 visiteurs naviguent en même temps sur votre boutique, Apache alloue 200 processus. La consommation mémoire monte en flèche, le serveur swap, les temps de réponse explosent. C’est courant pendant une promo, 200 visiteurs simultanés.
NGINX fonctionne différemment. Son architecture event-driven traite des milliers de connexions simultanées avec un nombre fixe de workers. Un benchmark publié par Koddr.io (2025) mesure la différence en conditions e-commerce réelles avec 80 utilisateurs concurrents :
| Métrique | Stack NGINX/PHP-FPM (“Lightning”) | Stack hybride Apache (“Hybrid”) |
|---|---|---|
| Actions checkout concurrentes | 4 809 | 3 035 |
| Perte sans cache Varnish | 7 % | 71 % |
| TTFB après migration | 220 ms | 800 ms |
Le dernier chiffre est le plus parlant. Un stack qui perd 71 % de ses résultats sans cache est un stack qui ne tient que par une béquille. En e-commerce, où une part importante du trafic est dynamique et non cachable, c’est un risque direct sur le chiffre d’affaires.
NGINX ne lit pas les fichiers .htaccess. Les règles de réécriture se configurent dans les server blocks. Si vos plugins dépendent de .htaccess, il faudra adapter. Ce n’est pas compliqué, mais ça demande une intervention serveur.
L’autre moitié de l’équation : PHP-FPM (FastCGI Process Manager). Sur un hébergement classique, PHP tourne via mod_php ou en mode CGI, lié au serveur web. PHP-FPM sépare les deux et permet de contrôler précisément les ressources allouées au traitement PHP.
Deux paramètres à connaître :
pm.max_children: le nombre maximum de processus PHP simultanés. Trop bas, les requêtes attendent en file. Trop haut, le serveur manque de RAM. Comptez 30-50 MB par processus WooCommerce.pm.max_requests: le nombre de requêtes avant recyclage d’un processus. Empêche les fuites mémoire à long terme, courantes avec les plugins WooCommerce.
Un site avec 80 % de visiteurs anonymes n’a pas les mêmes besoins qu’une boutique B2B où 90 % du trafic est connecté. PHP-FPM permet de dimensionner pour votre profil de charge réel.

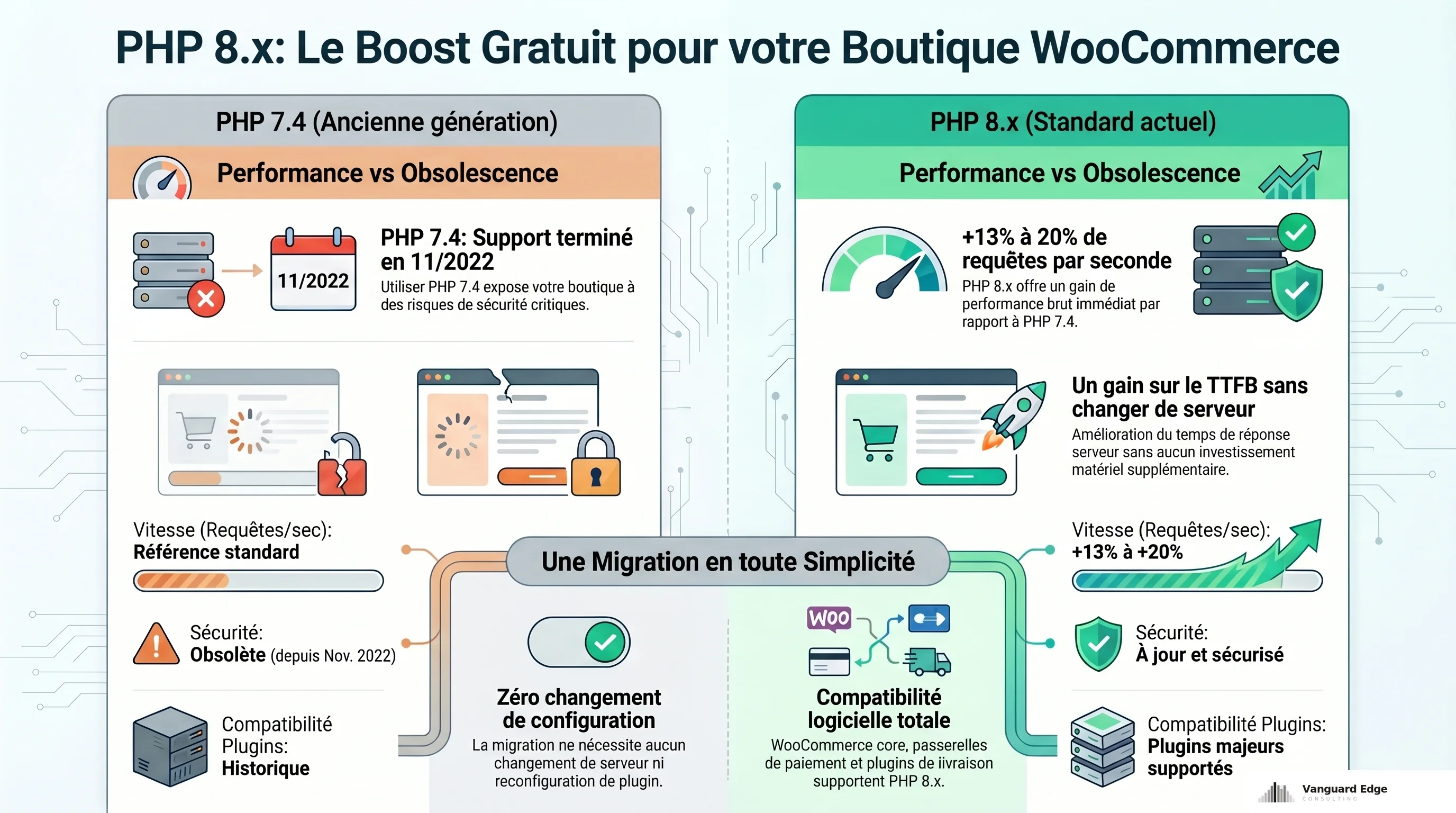
PHP 8.x : un gain gratuit que beaucoup ignorent
Avant de toucher à l’architecture, vérifiez votre version de PHP. Les benchmarks Pressidium et Kinsta convergent : PHP 8.x apporte entre 13 et 20 % de gain en requêtes par seconde par rapport à PHP 7.4. C’est un gain mesurable sur le TTFB, sans changer de serveur, sans toucher à un plugin, sans rien reconfigurer d’autre.
Beaucoup d’hébergements sont encore sur PHP 7.4 par défaut. Or le support de sécurité de PHP 7.4 est terminé depuis novembre 2022. Vous cumulez un risque de sécurité et un déficit de vitesse.
La migration demande de vérifier la compatibilité de vos plugins, mais sur les boutiques que j’accompagne, c’est rarement un problème : les plugins majeurs (WooCommerce core, les gateways de paiement, les plugins de livraison) supportent PHP 8.x depuis longtemps.
Redis : le cache objet que WooCommerce devrait toujours avoir
Le cache de page est inutile pour les utilisateurs connectés. Mais il existe un autre type de cache qui fait la différence sur les requêtes dynamiques : le cache objet.
WooCommerce stocke par défaut les résultats de certaines requêtes dans la table wp_options (mécanisme des “transients”). Ça reste une requête base de données pour lire le cache. Avec 200 sessions actives qui interrogent les prix, le stock et les variantes produit, MySQL est sollicité des deux côtés : les vraies requêtes ET le cache.
Redis stocke ces données en mémoire vive. Sessions utilisateur, contenu du panier, résultats de requêtes produit fréquentes : tout passe par la RAM au lieu de solliciter MySQL.
La combinaison NGINX + PHP-FPM + Redis est citée comme stack optimal WooCommerce par Koddr.io, Cloudways et les guides d’hébergement spécialisés WordPress. Chaque composant adresse un goulot d’étranglement différent. NGINX gère les connexions, PHP-FPM le traitement, Redis les requêtes répétitives.
Sur les boutiques que j’accompagne, l’ajout de Redis avec Object Cache Pro est souvent le changement avec l’impact le plus immédiat sur le TTFB des pages dynamiques. WooCommerce génère un volume de requêtes base de données disproportionné par rapport à un site WordPress classique, entre les variantes produit, les règles de prix et les calculs de livraison.
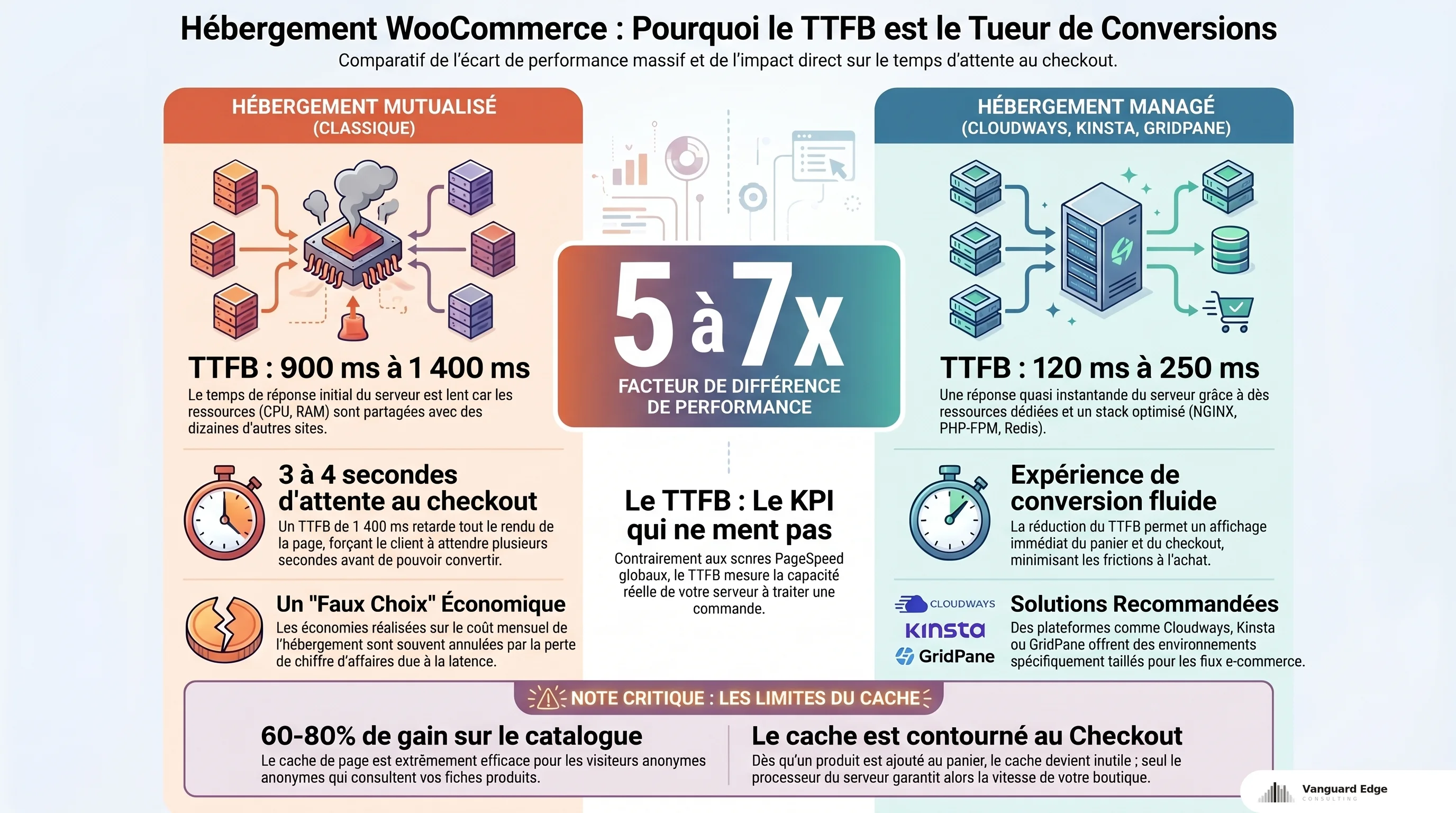
Hébergement mutualisé vs. managé : les chiffres parlent
La question “quel hébergement pour WooCommerce ?” se règle avec un seul KPI : le TTFB sous charge.
Les mesures publiées par Koddr.io et corroborées par plusieurs guides d’hébergement WordPress montrent un écart que je constate aussi sur le terrain :
- Hébergement mutualisé classique : TTFB entre 900 et 1 400 ms
- Hébergement managé (Cloudways, Kinsta, GridPane) : TTFB entre 120 et 250 ms
Facteur 5 à 7. Sur un checkout, 1 400 ms de TTFB veut dire que votre client attend 1,5 seconde avant que quoi que ce soit ne s’affiche. Ajoutez le rendu, et vous dépassez les 3-4 secondes. Les taux d’abandon augmentent.
L’hébergement mutualisé partage CPU, RAM et disque entre des dizaines de sites. Quand le voisin de serveur lance une tâche lourde, votre TTFB grimpe sans que vous n’ayez rien changé. Sur un site vitrine, c’est tolérable. Sur une boutique où chaque seconde de latence au checkout impacte le taux de conversion, ça ne l’est pas.
Si votre boutique génère du chiffre d’affaires, le mutualisé est un faux choix économique. Ce que vous gagnez par mois en hébergement, vous le perdez en conversions.
HPOS et WooCommerce 9.8 : ce qui change côté base de données
WooCommerce a un problème historique avec sa base de données. Pendant des années, les commandes ont été stockées comme des “posts” WordPress dans la table wp_posts, avec les métadonnées dans wp_postmeta. Une structure pensée pour des articles de blog, pas pour des transactions e-commerce.
HPOS (High-Performance Order Storage) corrige ça. Les commandes ont désormais leurs propres tables, avec des index dédiés. Les résultats sont concrets :
- Création de commandes 5 fois plus rapide (documentation officielle WooCommerce)
- Filtrage par
customer_id: 40 fois plus rapide que les requêtes surwp_postmeta(WooCommerce docs) - Sur les boutiques avec 50 000+ commandes, les gains atteignent 80 à 90 % sur les requêtes liées aux commandes (retours d’hébergeurs et cas documentés)
Pour les boutiques avec un historique conséquent, HPOS n’est plus optionnel. C’est la différence entre un back-office qui met 8 secondes à afficher les commandes et un qui met moins d’une seconde.
WooCommerce 9.8 (2025) va encore plus loin : -83,5 % de temps moyen par page dans l’admin, -73 % de taille JavaScript sur l’écran Orders (release notes WooCommerce). Un admin lent, c’est du temps gaspillé pour vos équipes. Du temps équipe, c’est de l’argent.
Autre changement à surveiller : le checkout block-based (WooCommerce 8.3+) est plus rapide que le shortcode classique (benchmarks WP Rocket).
WP-Cron : une bombe à retardement silencieuse
WordPress utilise un pseudo-cron déclenché par les visites. Chaque chargement de page vérifie s’il y a des tâches planifiées à exécuter : synchronisation de stock, emails transactionnels, recalcul des promotions.
Pendant un pic de trafic, WP-Cron se déclenche sur chaque requête. Un visiteur sur dix se retrouve à “porter” l’exécution d’une tâche de fond. Sa requête prend 2 secondes de plus. Sur un checkout, ça suffit à provoquer un abandon.
Le correctif prend 5 minutes :
- Désactiver WP-Cron dans
wp-config.php:define('DISABLE_WP_CRON', true); - Créer un cron système qui exécute
wp-cron.phptoutes les minutes
Les tâches tournent à intervalle régulier, de façon prévisible, sans impacter les visiteurs. Un facteur de latence aléatoire en moins.
Comment mesurer le vrai problème
Avant de changer quoi que ce soit à votre stack, mesurez le TTFB dans les bonnes conditions :
- Testez connecté, pas en mode incognito. Compte client actif, panier rempli. C’est la condition qui stresse le serveur.
- Testez pendant les pics. Un site qui tient à 50 visiteurs simultanés peut craquer à 200. Utilisez k6 ou Artillery pour simuler du trafic concurrent.
- Mesurez le TTFB, pas le score global. C’est le KPI qui isole la vitesse serveur.
- Comparez les pages : home vs. checkout. Si l’écart est massif, le problème est côté serveur.
Un TTFB checkout au-dessus de 800 ms en conditions de charge est un signal d’alerte. En dessous de 400 ms, le stack tient. Entre les deux, ça dépend de votre volume et de votre tolérance au risque pendant les pics.
Le TTFB impacte directement les Core Web Vitals, LCP et INP en tête. Un serveur lent retarde tout le rendu, et Google le mesure. Ça rejoint le tracking server-side et l’attribution e-commerce : si vous ne mesurez pas correctement d’où vient votre chiffre d’affaires, vous ne pouvez pas isoler l’impact de la vitesse sur vos conversions.
Les URLs dupliquées dans WooCommerce aggravent le problème : combinées à un serveur sous-dimensionné, elles multiplient les requêtes inutiles que Googlebot doit traiter.
Le diagnostic commence par le serveur
Si votre WooCommerce est lent sur le panier et le checkout mais que votre PageSpeed est bon, le problème n’est pas le front-end. C’est ce qui tourne en dessous.
NGINX + PHP-FPM + Redis + HPOS + PHP 8.x. Le socle. Pas un luxe, le minimum pour une boutique qui génère du chiffre d’affaires.
Avant de changer de thème ou de supprimer des plugins au hasard, mesurez votre TTFB en conditions réelles. Le diagnostic part de là.
Vous voulez savoir si l’infrastructure de votre boutique tient la route ? Le pré-audit est gratuit.
L'analyse en deux voix
Deux consultants discutent de ce sujet — données, cas terrain, implications business.
Lire la version texte
Aujourd'hui, on s'attaque à un paradoxe qui est incroyablement frustrant dans le monde du commerce en ligne.
C'est un scénario qu'on croise tout le temps.
Ah ouais, beaucoup trop souvent même !
Ouais, clairement.
Imagine la scène, on a une boutique en ligne, avec un Scorpage Pins & Sights qui est absolument parfait, un beau 90 ou plus, tout est dans le vert, le thème est ultra léger, les images sont compressées au pixel près, tout est l'air nickel.
La façade parfaite quoi !
Exactement.
Sauf que, au moment le plus critique, quand un client sort sa carte bleue et veut payer, le passage en casse met 4 ou 5 longues secondes à charger.
Pour donner une image, c'est comme si on admirait une voiture de sport avec une carrosserie super aérodynamique, polie à l'extrême, mais qui cacherait un moteur de tondeuse à gazon dès qu'il faut tracter une vraie charge.
C'est une super métaphore parce que c'est exactement ça.
En surface, ça brille, mais sous la contrainte, la mécanique lâche complètement.
Et cet effondrement, il coûte des fortunes en abandon de panier.
Et le réflexe de base, souvent, c'est la panique, non ?
Ah oui, totalement.
Les équipes techniques paniquent sur la partie visible.
Elles vont changer de thème, virer des dizaines d'extensions, rajouter encore une surcouche pour compresser les images.
Alors que le problème n'est pas du tout là.
Bah non.
C'est ça le truc.
On va se baser aujourd'hui sur un article hyper pointu de Vanguard's Edge Consulting, et selon leur analyse, le véritable coupable n'est quasiment jamais sur la partie esthétique C'est l'infrastructure Elmome.
Voilà.
L'auteur montre bien que la faille, elle se trouve dans les fondations du serveur.
D'accord.
Mais alors, la question qui se pose tout de suite, c'est pourquoi cette fameuse voiture de sport a l'air si rapide au début ?
C'est quoi cette illusion dont parle l'article ?
L'article de Vanguard's Edge pointe du doigt une illusion massive, qui est celle du cache de page.
Le fameux cache.
Comment ça marche concrètement pour tromper tout le monde ?
En gros, ça vient de la différence entre un visiteur anonyme et un acheteur actif.
Les systèmes de cache, genre WIP Rocket ou les réseaux CDN, génèrent une sorte de photographie statique d'une page web.
Ok.
Donc pour quelqu'un qui fait juste du lèche-vitrine sur le catalogue, le serveur ne calcule rien du tout ?
C'est exactement ça.
Il distribue juste cette photo pré-enregistrée.
L'auteur rappelle d'ailleurs que ça réduit les temps de chargement de 60 à 80%.
C'est un bouclier énorme.
Qu'est-ce qu'il se passe au moment de payer ?
La subtilité de WeCommerce, c'est que dès qu'il y a une action spécifique comme « se connecter à son compte » ou « afficher la page de paiement », ce bouclier est obligatoirement désactivé.
Obligatoirement ?
Parce qu'on manipule des données uniques j'imagine ?
Exact.
On ne peut pas servir une page statique avec le nom ou les frais de port d'un autre client, ce serait absurde.
Et c'est là que le cache saute.
A cet instant précis, chaque action déclenche une requête PHP directe vers la base de données.
Donc plus de filets de sécurité ?
Plus aucun.
Le système doit tout calculer en direct.
Les frais d'expédition, vérifier si le stock est là, appliquer les taxes.
Et c'est pour ça que l'obsession pour le score PageSpeed Insights est un vrai piège, selon l'article.
Parce que PageSpeed teste dans des conditions idéales, c'est ça ?
Exactement.
Des conditions de laboratoire sur une page d'accueil statique.
Il ne voit pas du tout ce qui se passe quand des dizaines de requêtes frappent le serveur de plein fouet pendant un pic d'affluence, genre un Black Friday.
C'est là que le Time to First Byte, le TTFB, explose littéralement.
D'accord.
C'est marrant parce que, si on veut bien visualiser le truc, se reposer juste sur le cache pour un e-commerce, c'est un peu comme… Comme quoi ?
C'est comme mettre des mannequins en carton super réalistes dans les allées d'un grand magasin.
L'idée, c'est de faire croire qu'il y a plein de vendeurs.
Visuellement, ça donne une belle illusion tant que les gens regardent depuis le couloir.
Ah oui, je vois très bien.
Et dès qu'un vrai client approche, touche un vêtement et pose une question pointue sur les tailles en réserve, le mannequin en carton ne sert plus à rien.
Il faut qu'un vrai employé aille fouiller dans les stocks en arrière-boutique.
Et si cet employé est débordé, tout le magasin se fille.
C'est une très bonne analogie.
Le vrai employé, ici, c'est le serveur.
Voilà.
Et si ce serveur doit encaisser tous ces calculs dynamiques d'un coup, la façon dont il est architecturé, c'est une question de survie.
Et c'est là que Vanguard Edge met le doigt sur la différence fondamentale entre Apache et Nginx.
Et ça, c'est crucial, parce qu'Apache reste le standard par défaut sur presque tous les hébergements.
Pourquoi est-ce qu'il s'effondre aussi vite sous la charge ?
Le mécanisme d'Apache, il est historique.
Il a été pensé à une époque où le web était beaucoup moins interactif.
Techniquement, selon l'article, Apache alloue un processus entier très lourd en ressources par visiteur.
Un processus complet juste pour une personne ?
Oui.
C'est comme un réceptionniste d'hôtel qui accompagnerait chaque client jusqu'à sa chambre, porterait ses valises et attendrait derrière la porte jusqu'à ce qu'il reparte.
Ah oui ?
C'est pas du tout optimisé ?
Donc, si on a 200 acheteurs en même temps, le serveur ouvre 200 processus ?
C'est ça.
Et la mémoire vive, la RAM, sature tout de suite.
Quand il n'y a plus de RAM, le serveur utilise son disque dur comme mémoire de secours.
C'est le fameux swap.
Et là, les temps de réponse s'écroulent.
D'où la mise en avant de NGINX par l'auteur.
La logique est différente.
Totalement différente.
NGINX fonctionne par événement.
Au lieu de bloquer un processus par personne, il utilise un nombre fixe de travailleurs, des workers, qui gèrent des milliers de connexions en même temps, de façon asynchrone.
Pour reprendre l'hôtel, c'est un réceptionniste central qui donne les clés à la volée sans quitter son bureau.
Exactement.
Et l'article cite d'ailleurs un benchmark de Coder.io de 2025, pour quantifier ça, avec 80 utilisateurs simultanés.
Oui, les chiffres de ce test, je les ai sous les yeux, ils sont assez brutaux.
Vas-y, rappelle-les pour voir.
Alors d'un côté, une infrastructure hybride basée sur Apache gère 3035 actions de checkout.
Mais le truc fou, c'est qu'elle subit une perte de 71% quand on enlève le cache, avec un TTFB qui monte à 800 ms.
71% de perte ?
C'est énorme.
Avec un TTFB compressé à 220 ms.
Faut vraiment insister sur ce 71% de perte avec Apache.
Perdre plus des deux tiers de sa capacité dès que le cache statique disparaît, c'est avoir un château de cartes.
Surtout en e-commerce où on peut rien cacher.
Exactement.
Et l'article souligne aussi l'importance de PHP-FPM.
C'est un gestionnaire qui isole l'exécution du code PHP.
On lui donne strictement 30 à 50 mégaoctets de mémoire par processus ou commerce.
Ce qui empêche les fuites de mémoire qui font cracher Apache d'habitude.
C'est ça.
Ca crée des cloisons étanches.
Mais du coup, j'ai une question.
Si Apache perd 71% de ses capacités sur du dynamique, c'est comme courir un sprint avec des boulets aux chevilles, pourquoi ça reste le standard absolu chez les hébergeurs en dévinette ?
Ah, la réponse tient dans un tout petit fichier de texte que beaucoup connaissent.
.htaccess.
Ah oui, le fameux .htaccess.
Voilà, c'est le couteau suisse du web classique.
N'importe quel plugin peut y mettre des règles de redirection en un clic et Apache lit ça en temps réel sans jamais redémarrer.
C'est ultra pratique pour l'utilisateur lambda, quoi.
C'est d'une commodité absolue.
Le problème, c'est que Nginx, pour rester rapide, refuse de lire ces fichiers distribués.
Toutes les règles doivent être codées en dur dans la configuration centrale du serveur.
Ce qui demande de vraies compétences en administration système.
Absolument.
Donc l'industrie a simplement décidé de sacrifier la performance pure sous charge pour garder cette facilité d'utilisation.
On garde un vieux moteur juste parce que le tableau de bord est plus simple, en fait.
C'est un peu ça.
Mais l'auteur de Vanguard Edge explique qu'une fois qu'on a mis en place la base Nginx, on peut s'attaquer à la vitesse de traitement pur.
Sans forcément acheter des serveurs hors de prix.
Exact.
La première règle souvent oubliée, c'est la version du langage.
Passer à PHP 8.quelque chose, ce n'est pas juste de la maintenance.
Ça apporte mécaniquement un gain de 13 à 20% de requêtes traitées en plus par seconde.
C'est énorme juste pour une mise à jour.
Oui.
Et l'article rappelle fermement que PHP 7.4 est obsolète et vulnérable depuis novembre 2022.
Oui, donc gagner 20% de perfs tout en bouchant des failles de sécurité, c'est indispensable.
Mais la vraie magie dans cette section de l'article, c'est l'introduction de Redis, non ?
Ah, Redis, c'est fondamental.
Vanguard Edge explique que WooCommerce est un logiciel très bavard.
Il passe son temps à solliciter la base de données mayesquuelles pour vérifier les prix, les stocks, via la table WP Options.
Ce qui sollicite le disque dur du serveur en permanence.
Exactement.
Même sur des disques SSD très rapides, ça prend du temps.
Redis, lui, prend ce cache-objet, donc les résultats fréquents, et les met directement dans la mémoire vive, la RAM.
Et la RAM est infiniment plus rapide qu'un disque physique.
C'est le jour et la nuit.
Pour imager ça, c'est l'exemple du barman dans un pub blindé de monde un samedi soir.
Vas-y, je t'écoute.
Bah, sans Redis, chaque fois qu'on commande la bière la plus populaire, le barman doit descendre à la cave, donc le disque dur moyesquuelles, tirer une pinte et remonter.
Au bout de dix commandes, le mec est épuisé et la file d'attente est dingue.
C'est sûr que ça bouchonne.
Et Redis, c'est l'équivalent de mettre un petit fût de cette bière directement sous le comptoir.
La commande tombe, le barman se baisse, paf, c'est instantané.
J'adore.
C'est exactement ça, un gain de temps monumental.
Donc Nginx gère la foule à la porte, PHP-FPM prend les commandes calmement, et Redis sert depuis le comptoir.
Le serveur respire enfin.
Bon, ça c'est pour le matériel et l'infrastructure.
Mais l'article va plus loin.
Il dit que si le logiciel lui-même range mal ses données, ça bloque quand même.
Oui, on touche à la dette technique de WooCommerce.
Pendant des années, le système sauvegardait les commandes des clients selon la même logique qu'un simple article de blog.
Attends, une commande e-commerce rangée comme un article de blog ?
Ouais.
Tout était entassé dans une seule table de la base de données, la WP-Post.
Mais c'est un non-sens total.
C'est le péché originel de WordPress.
A la base, c'est fait pour publier des billets.
Mais une commande, c'est complexe.
C'est une adresse, un taux de TVA, un historique bancaire.
Forcer tout ça dans une structure pour du texte brut, ça a créé un goulot d'étranglement sévère.
Et c'est là que l'article parle du HPOS, le High Performance Order Storage.
Exactement.
L'idée de HPOS, c'est enfin d'offrir aux commandes leur propre table dédiée, sans se mélanger avec les articles.
Et les chiffres partagés par l'auteur sont dingues.
Créer une commande devient 5 fois plus rapide.
Et filtrer l'historique d'un client, c'est 40 fois plus rapide.
40 fois, oui.
Pour une boutique qui a plus de 50 000 commandes en base, l'article parle d'un gain de fluidité de 80 et 90 %.
Et avec la mise à jour WooCommerce 9.8 de 2025, le temps de chargement du back-office, donc l'administration, a été réduit de 83,5 %.
On passe d'une usine à gaz à un truc qui répond en temps réel.
C'est fou.
Clairement.
Mais au milieu de tout ça, il y a un dernier problème abordé par Vanguard Edge.
Et honnêtement, ça ressemble à une mauvaise blague.
Ah oui, l'histoire du WP Cron.
J'ai lu ça.
C'est aberrant.
Tu m'étonnes.
En gros, le système n'a pas d'horloge interne indépendante pour lancer ses tâches de fond, comme envoyer des e-mails ou synchroniser les stocks.
Et donc, il utilise quoi ?
Un déclencheur factice.
Il se grève sur les visites des clients.
Le système attend qu'un utilisateur charge une page et lui impose de faire tourner la tâche de fond en plus de sa propre navigation.
Donc, en plein pic de trafic, un acheteur sur dix se mange deux secondes de chargement en plus juste parce que son clic a lancé une synchronisation en arrière-plan.
C'est exactement ça.
Et sur une page de paiement, deux secondes de gel inexpliquée, le client croit que sa carte a planté et il s'en va.
C'est absurde pour un logiciel professionnel.
C'est comme si, je sais pas, le directeur d'un supermarché disait que le dixième client qui arrive à la caisse doit obligatoirement passer la serpillère dans le rayon fruits et légumes avant de pouvoir payer.
C'est tellement ça.
C'est la garantie de rendre le client fou.
Heureusement, l'auteur précise que c'est hyper simple à corriger pour un technicien.
On désactive ce déclencheur virtuel et on met une vraie tâche planifiée sur le système d'exploitation du serveur.
Ça prend cinq minutes et ça sauve des milliers de ventes.
D'accord, donc on a vu les fondations, le cache qui saute, la RAM, la base de données mal rangée et ces tâches parasites.
Mais pour ceux qui nous écoutent, l'article donne quoi comme méthode pour mesurer tout ça de façon fiable ?
La méthodologie de Vanguard Edge est très stricte.
Tester la page d'accueil en navigation privée, ça sert à rien.
Il faut se connecter, c'est ça ?
Oui, se connecter, mettre des trucs dans le panier pour bien désactiver le cache et utiliser des outils pour simuler plein de visiteurs en même temps.
L'indicateur clé, c'est ce fameux TTFB, le temps de réponse du serveur.
Et c'est quoi les seuils d'alerte ?
L'article est binaire là-dessus.
Si TFB dépasse les 800 ms sous la charge, c'est une alerte rouge absolue.
L'architecture va céder.
Et un système sain ?
Il doit rester en dessous des 400 ms.
Et c'est là qu'on voit le gouffre entre les hébergements.
Sur du mutualisé standard, on plafonne souvent entre 900 et 1400 ms en dynamique.
Alors que sur une inframe managée, taillée avec NGINX et Redis comme préconisé, on tombe entre 120 et 250 ms.
Et chaque fraction de seconde gagnée, c'est du chiffre d'affaires préservé.
Le message, c'est vraiment de consolider le socle avant de s'amuser à changer la couleur d'un bouton.
Ce qui est très logique.
D'ailleurs, l'article recommande à ceux qui doutent de leur infrastructure de faire un pré-audit de performance.
Il y a un outil gratuit à l'adresse exacte chiffre.audit.vanguard-edge-consulting.com.
C'est vraiment le point de départ pour avoir les vraies données de son propre moteur.
C'est ça.
Et pour clore cette analyse de l'article, l'auteur soulève une réflexion beaucoup plus large qui fait réfléchir.
Ah ouais ?
Laquelle ?
Quand on voit le niveau d'ingénierie chirurgicale dont on vient de parler, les serveurs événementiels, la RAM dédiée, la refonte des bases de données.
Ouais, ça fait beaucoup pour un simple CMS.
Une entreprise hyper complexe qui avance juste au masqué, derrière un tableau de bord qu'on connaît bien.
C'est une excellente question pour terminer.
On avait commencé avec l'image de la voiture de sport au moteur défaillant.
On comprend bien que pour supporter la vraie charge financière du e-commerce d'aujourd'hui, mettre un coup de poliche, ça suffit plus.
Ah, ça non !
Il faut vraiment ouvrir le capot, virer la vieille mécanique et forger l'architecture lourde qu'une vraie machine transactionnelle demande.
Ce sont des fondations invisibles, mais c'est là que se joue toute la viabilité de la boutique.
Comment diagnostiquer la lenteur WooCommerce
Durée : 20 min- 1
Tester connecté sous charge réelle
Testez votre site avec un compte client actif et un panier rempli pendant les pics de trafic. Utilisez k6 ou Artillery pour simuler du trafic concurrent. Un site qui tient à 50 visiteurs peut craquer à 200.
- 2
Mesurer le TTFB sur les pages dynamiques
Comparez le TTFB de la page d'accueil avec celui du checkout via Chrome DevTools. Un écart massif indique un problème serveur. Au-dessus de 800 ms en conditions de charge, c'est un signal d'alerte.
- 3
Vérifier la version PHP du serveur
Contrôlez que votre hébergement tourne sur PHP 8.x. Le passage depuis PHP 7.4 apporte 13 à 20 % de gain en requêtes par seconde sans changer de serveur ni de plugin.
- 4
Auditer le stack serveur et le cache objet
Vérifiez si votre stack utilise NGINX + PHP-FPM plutôt qu'Apache, et si Redis est en place pour le cache objet. Sans Redis, les sessions WooCommerce sollicitent MySQL des deux côtés : requêtes réelles et cache.
Questions fréquentes
Quel hébergement choisir pour une boutique WooCommerce ?
Un hébergement managé avec stack NGINX + PHP-FPM + Redis (Cloudways, Kinsta, GridPane). Les mesures montrent un TTFB entre 120 et 250 ms sur hébergement managé contre 900 à 1 400 ms sur mutualisé, soit un facteur 5 à 7. Sur un checkout, cette différence se traduit directement en taux d'abandon.
WP Rocket suffit-il pour accélérer WooCommerce ?
Non, pas pour les pages dynamiques. WP Rocket documente lui-même que le panier, le checkout et le compte client ne peuvent pas exploiter le full-page cache. Le cache de page aide sur les pages catalogue anonymes (60 à 80 % de gain), mais dès qu'un visiteur se connecte ou ajoute un produit au panier, c'est le stack serveur qui détermine la vitesse.
Quelle version PHP utiliser pour WooCommerce en 2026 ?
PHP 8.x minimum. Les benchmarks Pressidium et Kinsta mesurent entre 13 et 20 % de gain en requêtes par seconde par rapport à PHP 7.4, sans changer de serveur ni de plugin. PHP 7.4 n'a plus de support de sécurité depuis novembre 2022. Les plugins majeurs (WooCommerce core, gateways de paiement, plugins de livraison) supportent PHP 8.x depuis longtemps.