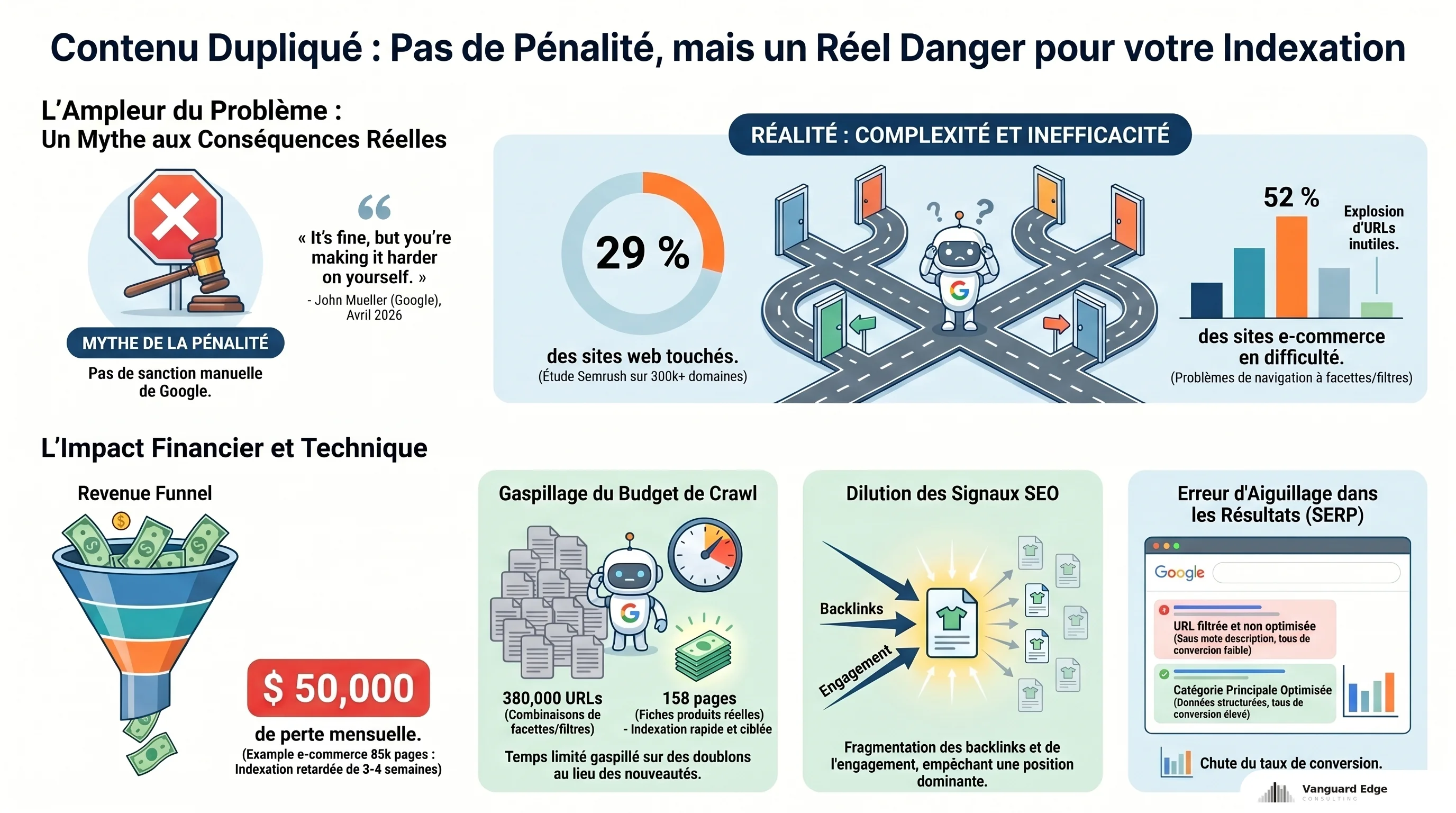
29 % des sites web ont des problèmes de contenu dupliqué, d’après une étude Semrush sur plus de 300 000 domaines. Sur les boutiques e-commerce, le chiffre est pire : les catalogues produit, les filtres de navigation et les plateformes elles-mêmes génèrent des doublons de manière structurelle. Et pourtant, Google ne vous pénalisera pas pour ça. John Mueller l’a reconfirmé en avril 2026 : la duplication de contenu ne déclenche aucune pénalité manuelle ni algorithmique. Alors où est le problème ? Il est dans ce que vos doublons font à vos signaux SEO. Quand vos URLs se contredisent, Google perd du temps, indexe les mauvaises pages, et votre chiffre d’affaires s’en ressent.
Pas de pénalité, mais un vrai problème d’indexation
L’idée d’une « pénalité pour contenu dupliqué » est un mythe qui circule depuis plus de dix ans. La documentation officielle de Google est limpide : le moteur choisit une URL canonique parmi les doublons et ignore les autres. Pas de sanction, pas de déclassement punitif.
Mueller a été direct dans sa dernière prise de parole : « It’s fine, but you’re making it harder on yourself. » En clair, Google s’en sort, mais vous lui compliquez la tâche. Et quand un moteur de recherche doit deviner ce que vous voulez, il ne devine pas toujours bien.
D’abord, le crawl : Googlebot dispose d’un budget de crawl limité par site. Chaque URL dupliquée qu’il visite, c’est une page utile qu’il ne visite pas. Sur un catalogue de plusieurs milliers de produits, ça ralentit l’indexation des nouveautés. Un cas documenté par HigherVisibility illustre l’ampleur du problème : un site e-commerce de 85 000 pages dont les nouveaux produits mettaient 3 à 4 semaines à apparaître dans Google, avec une estimation de 50 000 $ par mois de chiffre d’affaires perdu pendant ce délai.
Ensuite, la dilution des signaux. Quand des backlinks, du trafic et de l’engagement se répartissent entre trois URLs qui affichent le même contenu, aucune des trois ne concentre assez de « poids » pour bien se positionner. Le principe est le même que pour le poids des pages et leur impact SEO en e-commerce : ce qui se disperse perd en efficacité.
Enfin, la mauvaise URL dans les résultats. Si Google choisit une URL filtrée (avec des paramètres) comme canonique au lieu de votre page de catégorie principale, c’est cette version appauvrie qui apparaît dans la SERP. Pas de meta description optimisée, pas de données structurées à jour. Le trafic arrive, mais les conversions ne suivent pas.
Pourquoi les boutiques en ligne sont les plus touchées
Sur un blog, les doublons sont rares. Sur une boutique, ils sont structurels. C’est la nature même des plateformes e-commerce qui les crée, et c’est ce qui rend le SEO e-commerce si différent du SEO classique.
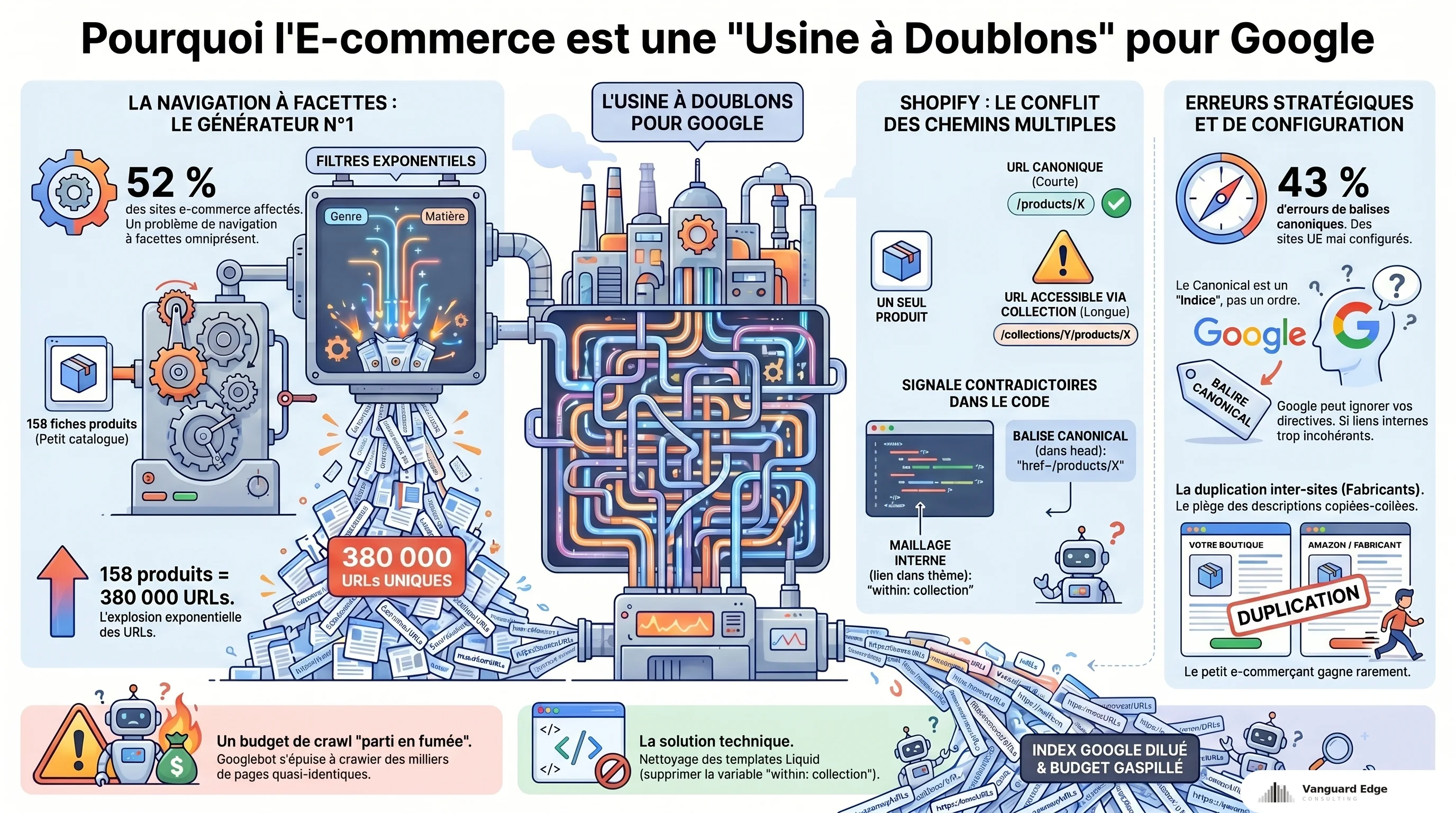
La navigation à facettes : le générateur de doublons n°1
52 % des sites e-commerce ont des problèmes liés à leur navigation à facettes, d’après un audit DeepCrawl sur un panel européen. Le mécanisme est simple : chaque combinaison de filtres (taille, couleur, prix, marque) génère une URL unique. Google a documenté un cas où 158 produits avaient engendré 380 000 URLs via les combinaisons de facettes. 158 fiches produit. 380 000 URLs dans l’index.
Le résultat : Googlebot passe des jours à crawler des pages quasi-identiques au lieu d’indexer vos vrais contenus. Votre budget de crawl part en fumée. Sur Shopify spécifiquement, 70 à 90 % du crawl budget brûlé sur les facettes et autres URLs paramétrées est désormais documenté avec la nouvelle doctrine Google 2026 (limite HTML 2 Mo, latence DB qui prime sur la taille du site).
Shopify et les chemins multiples
Sur Shopify, chaque produit a une URL canonique en /products/nom-du-produit. Mais quand ce produit est accessible via une collection, la plateforme crée aussi /collections/nom-collection/products/nom-du-produit. Deux URLs, même contenu. Shopify pose un canonical automatique vers /products/..., ce qui règle le problème en théorie.
En pratique, le thème Liquid utilise souvent la variable within: collection dans les liens internes, ce qui fait pointer tout votre maillage vers les URLs de collection au lieu de l’URL canonique. Vous envoyez un canonical qui dit « la vraie page est là-bas » et des liens internes qui disent « non, la vraie page est ici ». Google reçoit deux signaux contradictoires. Le correctif documenté par Amsive : supprimer within: collection de vos templates Liquid pour que les liens internes pointent vers la même URL que le canonical.
Sur WooCommerce, le problème prend une autre forme. Sans configuration explicite, les deux versions d’URL coexistent sans aucun signal de préférence. Le plugin SEO (Yoast, Rank Math) gère le canonical, mais encore faut-il que vos paramètres serveur et votre stack technique soient alignés.
Les descriptions fabricant copiées
Un problème que beaucoup de boutiques ignorent : les fiches produit qui reprennent mot pour mot la description du fabricant. Quand 200 revendeurs publient le même texte sur le même produit, Google doit choisir quelle version mérite de ranker. Et c’est rarement le petit e-commerçant qui gagne face à Amazon ou au fabricant lui-même. D’après Ahrefs, cette duplication inter-sites est l’une des premières causes de pages e-commerce qui n’apparaissent jamais dans les résultats de recherche.
Comment Google choisit l’URL canonique (et pourquoi il se trompe)
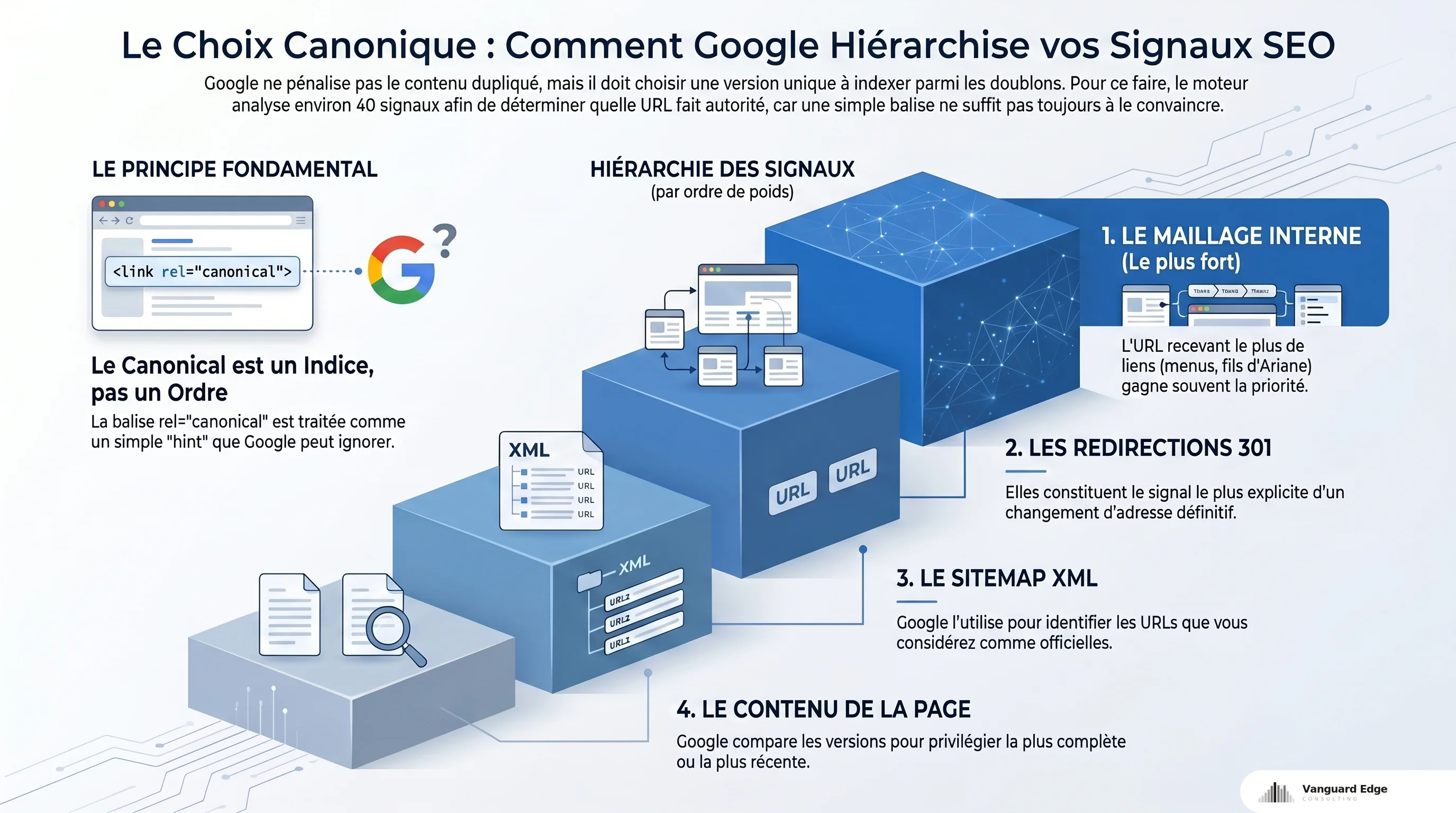
Google utilise environ 40 signaux pour déterminer quelle URL garder parmi un groupe de doublons, d’après sa propre documentation. Ce n’est pas du hasard, mais ce n’est pas non plus un processus que vous contrôlez entièrement.
Le canonical est un indice, pas un ordre
C’est le point que la plupart des référenceurs sous-estiment. La balise rel="canonical" est traitée par Google comme un « hint » (indice), pas comme une directive. Google peut l’ignorer s’il estime que d’autres signaux la contredisent. Search Engine Land a documenté plusieurs cas où Google avait choisi une URL différente de celle indiquée par le canonical, notamment quand le maillage interne pointait massivement vers une autre version.
43 % des sites e-commerce européens audités par Semrush avaient des erreurs de balise canonical. Pas l’absence de canonical, mais une canonical pointant vers la mauvaise URL. C’est pire que pas de canonical du tout : vous envoyez un signal actif qui oriente Google dans la mauvaise direction.
Les quatre signaux qui pèsent
Le maillage interne est le signal le plus fort en pratique. L’URL qui reçoit le plus de liens internes (menu, breadcrumbs, liens depuis les fiches produit) sera celle que Google favorise. J’en parle en détail dans l’article sur l’impact du maillage interne sur le crawl et le PageSpeed : la cohérence de votre architecture de liens dicte ce que Google considère comme vos pages principales.
Les redirections 301 sont le signal le plus explicite. Elles disent à Google « cette page a déménagé définitivement ». Après une migration, chaque ancienne URL doit rediriger vers la nouvelle. Sur les boutiques que j’audite, je vois régulièrement des refontes à moitié faites : les pages principales redirigent, mais les catégories secondaires et les anciens filtres traînent pendant des mois sans redirection.
Le sitemap XML liste les URLs que vous présentez à Google comme vos pages officielles. Si votre sitemap contient des URLs filtrées ou des variantes que vous ne voulez pas indexer, vous envoyez un signal contradictoire avec votre canonical.
Le contenu de la page lui-même joue aussi : Google compare les versions et peut préférer celle qui a le contenu le plus complet ou la date la plus récente.
Auditer vos signaux en 30 minutes
Avant de corriger quoi que ce soit, il faut savoir où sont les contradictions. Voici le process que j’applique au début de chaque audit technique.
Ouvrez votre sitemap XML. Parcourez-le : est-ce qu’il contient des URLs de filtres, des pages de tags, des variantes avec paramètres ? Si oui, elles n’ont rien à faire là. Un sitemap propre ne contient que les pages que vous voulez voir apparaître dans Google.
Prenez 5 à 10 pages stratégiques : accueil, catégories principales, vos best-sellers. Sur chacune, vérifiez la balise canonical dans le code source. Est-ce qu’elle pointe vers l’URL présente dans le sitemap ? Si la canonical et le sitemap ne sont pas d’accord, vous avez trouvé votre première contradiction.
Troisième vérification : le maillage interne. Vos liens de navigation, vos breadcrumbs, vos liens depuis les fiches produit pointent-ils vers les mêmes URLs que le sitemap et les canonicals ? Un crawl rapide avec Screaming Frog en mode « list » sur vos 50 pages principales révèle les incohérences en quelques minutes.
L’objectif, c’est la cohérence entre les trois systèmes. Mueller l’a dit autrement : le SEO, c’est du « search-engine whispering ». Vous ne forcez pas Google. Vous alignez vos signaux pour qu’il comprenne ce que vous voulez sans ambiguïté.
Ce que les IA génératives changent en 2026
Les réponses générées par IA dans les résultats de recherche (AI Overviews de Google, citations Perplexity, Bing Copilot) ajoutent une couche au problème de canonicalisation.
Les modèles de langage qui alimentent ces fonctionnalités ont besoin de signaux clairs pour identifier la source faisant autorité sur un sujet. Quand votre contenu existe en cinq versions sous cinq URLs différentes, le modèle hésite et peut attribuer l’information à un concurrent dont la structure est propre. Search Engine Land a soulevé ce point début 2026 : vos signaux de canonicalisation travaillent maintenant sur deux fronts, le crawl classique et les citations IA.
Plan d’action concret
Si vous gérez une boutique Shopify, commencez par trois choses. Vérifiez que vos templates Liquid ne contiennent pas within: collection dans les liens produit. Ajoutez un noindex sur les pages de tags et de filtres via votre thème ou une app comme JSON-LD for SEO. Et passez votre sitemap au peigne fin pour retirer les URLs parasites.
Sur WooCommerce, installez ou reconfigurez votre plugin SEO pour que les canonicals pointent vers les bonnes URLs. Vérifiez que vos pages de filtres personnalisés (si vous utilisez un plugin de filtres avancés) ne sont pas indexables par défaut. Et si vous avez fait une migration récente, lancez un crawl pour identifier les anciennes URLs qui répondent encore en 200 au lieu de rediriger.
Dans les deux cas, l’audit de cohérence entre sitemap, canonicals et maillage interne prend 30 minutes. Le retour sur investissement se mesure en semaines d’indexation gagnées et en pages correctement positionnées.
J’ai vu des boutiques récupérer des positions sur des catégories entières simplement en alignant ces trois signaux. Pas de refonte, pas de nouveau contenu, pas de backlinks. Juste de la cohérence.
Vous voulez savoir si vos URLs envoient les bons signaux ? Le pré-audit est gratuit : audit.vanguard-edge-consulting.com.
L'analyse en deux voix
Deux consultants discutent de ce sujet — données, cas terrain, implications business.
Lire la version texte
près d'un tiers du web mondial est en fait littéralement cassé de l'intérieur.
Ouais, c'est ça.
Et le pire, c'est que presque personne ne s'en rend compte.
On commence vraiment fort aujourd'hui avec une statistique assez incroyable.
C'est le moins qu'on puisse dire, ouais.
C'est tiré d'une étude de SEMrush qui a porté sur plus de 300 000 domaines.
Et les résultats montrent que 29% des sites souffrent de problèmes sévères de contenu dupliqué.
29% ?
C'est un chiffre colossal en fait.
Ah bah carrément.
Mais il faut bien comprendre que ça, c'est une moyenne globale.
Parce que si on isole le cas spécifique des boutiques en ligne, la situation devient vraiment, vraiment critique.
Ouais, c'est un autre niveau.
Exactement.
Et c'est d'ailleurs le point de départ d'une analyse passionnante qui a été publiée récemment par Vanguard Edge Consulting.
Ce qui sert de base à notre décryptage d'aujourd'hui du coup.
Tout à fait, parce que selon Vanguard Edge, dans le secteur de la vente en ligne, le contenu dupliqué n'est pas juste une simple erreur de parcours.
C'est un défaut structurel profond.
Un vrai vice de fabrication quoi.
C'est exactement ça.
Et la mission de cette plongée documentaire, c'est justement de comprendre ce qui se passe sous le capot.
On va tordre le cou à ce mythe tenace, tu sais la fameuse pénalité du moteur de recherche.
Ah, ce fameux mythe, ouais.
Pour découvrir la vraie nature du gros problème.
Une fuite financière qui est totalement invisible.
Totalement.
Et surtout, on va voir comment aligner les signaux informatiques pour régler ça.
Sans avoir à toucher à une seule ligne de code complexe.
Ok, on décortique tout ça.
La priorité absolue ici, c'est vraiment de démonter la plus grande légende urbaine du référencement.
Ouais, il faut qu'on en parle de ça.
Parce que depuis une bonne dizaine d'années, il y a une peur bleue qui circule chez les gérants de sites.
La peur du gendarme en gros.
Voilà.
L'idée qu'un algorithme punitif viendrait, je sais pas, distribuer des mauvais points et bannir les pages qui se répètent ?
C'est vrai qu'on a tous un peu cette image en tête.
Enfin, on s'imagine le moteur de recherche comme une sorte de professeur ultra sévère.
C'est ça, le prof qui repère les tricheurs.
Ouais, et qui les envoie direct au fond de la classe avec un zéro pointé.
Sauf que l'analyse de Vanguard Judge balaye complètement cette idée reçue.
Il s'appuie sur du concret, hein.
Absolument.
Il rappelle qu'en avril 2026, John Muller, qui parle quand même au nom du plus grand moteur de recherche mondial...
Rien que ça.
Voilà.
Il a réaffirmé publiquement qu'il n'y a aucune pénalité, ni manuelle, ni algorithmique.
Zéro pénalité pour le contenu dupliqué.
Zéro.
La documentation officielle explique simplement que le système va essayer de choisir une seule adresse principale parmi les doublons.
Et il va juste ignorer le reste.
C'est ça.
Et la phrase exacte de Muller résume parfaitement le problème.
Il dit « c'est ok, mais vous vous compliquez la tâche ».
« C'est ok, mais vous vous compliquez la tâche ».
C'est fou comme formulation.
Ouais, c'est presque bienveillant, en fait.
Pour bien visualiser ce que ça implique, pour ceux qui nous écoutent, il faut imaginer un livreur, d'accord ?
D'accord.
Un livreur à qui l'on donnerait trois cartes routières différentes pour trouver exactement la même maison.
Ah ouais, l'angoisse.
Le livreur ne va pas se mettre en colère, ne va pas rayer la maison de sa tournée ou confisquer le colis juste pour punir le destinataire.
Non, ce n'est pas son but.
Son travail, c'est de livrer.
Sauf qu'avec trois itinéraires qui se contredisent, il va perdre un temps fou.
Un temps précieux, ouais.
Il va tourner dans le quartier, il va vérifier chaque impasse, chaque petite rue.
Et à la fin, complètement épuisé, il y a de fortes chances qu'il laisse le paquet devant la mauvaise porte.
La métaphore est super juste.
Parce que ce temps perdu par le livreur, c'est la mécanique même de ce qu'on appelle le budget crawl.
Le fameux budget crawl.
Voilà.
Les robots d'exploration, ils n'ont pas un temps infini à accorder à un site.
Ils ont un quota très précis.
Ils sont pressés, quoi.
C'est ça.
Donc, s'ils passent toute leur journée à lire dix fois la même fiche produit, juste parce qu'il y a des adresses différentes...
Ils ne vont pas voir l'Ouest.
Exactement.
Ils n'ont plus le temps de découvrir les vraies nouveautés du catalogue.
Ce qui est fascinant ici, c'est l'impact financier extrêmement concret que cette perte d'efficacité génère.
Parce qu'on parle de vrais sous, là ?
Ah oui.
L'analyse de Vanguard Edge rapporte un cas documenté par l'agence Higher Visibility.
C'était sur une boutique de 85 000 pages.
Attends, 85 000 pages.
C'est un catalogue énorme, ça.
Énorme, oui.
Qu'est-ce qui a bien pu se passer pour que ça tourne au désastre financier ?
La machine s'est littéralement noyée dans les doublons.
Ah ouais.
Les robots perdaient tellement de ressources habilitées des impasses que lorsqu'un nouveau produit était ajouté au catalogue, ils mettaient 3 à 4 semaines avant d'apparaître dans les résultats de recherche.
3 à 4 semaines ?
Mais c'est une éternité en e-commerce.
C'est la mort.
Pendant presque un mois, ces articles n'existaient tout simplement pas pour les clients.
Et financièrement, ça donne quoi ?
Le manque à gagner lié à ce délai d'indexation a été chiffré.
Vas-y.
Une perte sèche estimée à 50 000 dollars de chiffre d'affaires chaque mois.
50 000 dollars par mois qui s'est l'apport.
Juste parce qu'un robot s'épuise à lire les mauvaises pages.
C'est hallucinant.
C'est le prix d'un mauvais budget de crôle.
Mais au-delà du temps perdu, il y a aussi un deuxième effet destructeur qui est mis en avant dans l'article.
La dilution, c'est ça ?
Exactement.
La dilution des signaux.
Et là, c'est purement mathématique.
Explique.
Ben si, l'engagement des visiteurs, le trafic et les liens entrants se divisent sur 3 adresses qui sont identiques.
La force est divisée, forcément.
C'est ça.
La force de frappe de la page est divisée par 3.
Donc aucune des versions n'accumule assez de puissance pour dépasser les concurrents.
C'est logique.
Mais on n'a même pas encore parlé du pire scénario.
Ah bon ?
Il y a pire que 50 000 dollars par mois ?
Ben oui.
Que se passe-t-il quand le moteur de recherche, à force de tourner en rond avec ses fameuses 3 cartes routières, il finit par valider la mauvaise adresse web ?
Je vois le genre.
Au lieu d'afficher la belle page de la catégorie principale bien propre, il affiche une adresse générée par un obscur filtre de couleurs ou le prix.
Exactement.
Le client clique dans les résultats, mais il arrive sur une page sans description optimisée.
Sans mise en page travaillée, un truc tout cassé.
Voilà.
La vitrine est repoussante, donc forcément la conversion s'effondre.
C'est terrible.
Le trafic arrive, on a réussi à faire venir les gens, mais les ventes ne suivent pas.
C'est pour ça qu'on voit bien que l'enjeu, ce n'est vraiment pas d'éviter une punition.
Non, c'est de la survie économique.
C'est d'arrêter de saboter sa propre rentabilité par une désorganisation interne, tout simplement.
C'est là que ça devient vraiment intéressant.
Parce que si tout ce gâchis financier vient d'une multiplication des adresses web, pourquoi le secteur du commerce en ligne est-il autant touché ?
Je veux dire, selon Vancouver Edge, ce genre de problème est anecdotique sur un bloc classique.
Complètement anecdotique, oui.
Mais sur les boutiques, c'est une véritable épidémie mondiale.
Et le principal accusé, c'est une fonctionnalité que l'on utilise tous les jours.
Les filtres.
La navigation par filtre, oui.
La fameuse navigation à facettes.
C'est ça.
Alors, selon un audit de Deepcrawl qui est cité dans l'étude, 52% des sites e-commerce souffrent de dysfonctionnements liés à ces filtres.
Plus d'un site sur deux, c'est fou.
Et à l'origine, c'est pensé pour l'ergonomie.
Entrée par taille, par couleur, par marque, c'est super pratique.
C'est indispensable même pour l'utilisateur.
Sauf que techniquement, la façon dont les plateformes gèrent ces tris en coulisses, c'est souvent catastrophique.
Il faut comprendre la mécanique qui opère en arrière-plan.
Chaque fois qu'on clique sur un filtre, disons chaussures rouges en taille 42.
Un grand classique.
Le système génère instantanément une toute nouvelle adresse web.
Et le chiffre le plus dingue de l'article de Vanguard Edge vient d'un cas d'école documenté par Google le même.
Ah oui, cette statistique est folle.
Une petite boutique avec un catalogue de seulement 158 produits.
C'est minuscule, 158 produits.
Ça a fini par générer 380 000 adresses web différentes.
C'est vertigineux.
Mais comment 158 produits peuvent-ils se multiplier à ce point ?
Ça n'a aucun sens.
C'est la magie noire de la combinatoire mathématique.
La magie noire, c'est le bon terme.
Parce que le moteur de recherche, lui, il ne voit pas une seule paire de chaussures avec des options.
D'accord.
Il voit une adresse pour la chaussure rouge, une autre adresse pour la rouge en taille 42, une autre pour la rouge en taille 42 classée par prix croissant.
Ah ouais, ça sent pile.
Chaque croisement de filtres crée une nouvelle URL dans l'index.
Donc pour le budget de Kroll, c'est un vrai trou noir.
Les robots s'épuisent.
Ils s'épuisent à explorer 380 000 pages qui sont, ben, à une virgule près, fondamentalement identiques.
Mais on pourrait se dire que les grandes plateformes de création de boutiques ont prévu le coup, non ?
On pourrait croire ça, oui.
Des solutions géantes, genre Shopify, ça doit être optimisé d'office quand on lance sa boutique.
Eh ben, c'est très contre-intuitif, mais c'est exactement l'inverse.
Non, sérieux ?
Chaque outil a ses propres failles natives.
Par exemple, sur Shopify, le grand piège identifié par Vanguard Edge, c'est la gestion des chemins multiples.
Comment ça ?
Prenons un exemple simple.
Un article possède une adresse officielle courte.
OK, l'adresse de base du produit.
Voilà.
Mais si on clique sur cet article depuis une catégorie spécifique de la boutique...
Oui ?
Le système va créer une adresse longue qui inclut le nom de la catégorie dans l'URL.
D'accord, donc on a deux adresses pour le même objet.
Mais tant Shopify intègre bien une petite ligne de code invisible, tu sais, la fameuse valise canonique.
Oui, le rôle canonical.
C'est ça.
Juste pour dire au moteur, hé, voici la version officielle courte, il n'y aurait le reste.
Non.
Alors oui, la valise canonique pointe bien vers l'adresse courte.
Bon, ben alors c'est réglé.
Sauf que le problème, c'est le squelette même de Shopify, ce qu'on appelle le thème liquide.
Ce code, il utilise par défaut une variable qui s'appelle WithinCollection.
Et cette variable force la quasi-totalité des liens internes de la boutique à pointer vers l'adresse longue.
Mais c'est le serpent qui se mord la queue, ce truc.
Exactement.
D'un côté, le site crie en silence « Regardez la page courte via sa valise », mais de l'autre côté, toute la navigation interne, les menus, envoient les robots vers la page longue.
C'est une contradiction totale des signaux.
C'est absurde.
Et j'imagine que si on décide de monter sa propre boutique sur mesure avec WooCommerce pour éviter ça, on n'est pas forcément à l'abri non plus.
Ah, loin de là.
Sur WooCommerce, le défi est différent, mais il est bien là.
C'est quoi le piège avec eux ?
Ce n'est plus une contradiction de signaux, comme sur Shopify, c'est souvent une absence totale de signaux.
Le vide intersidéral.
Voilà.
Les différentes versions de pages coexistent, et sans l'intervention d'un plugin très, très bien configuré, le système ne donne aucune indication claire au moteur de recherche.
Donc le robot doit se débrouiller tout seul.
C'est ça.
Et le pire, c'est que même avec un plugin SEO installé, il faut que les réglages du serveur web soient parfaitement synchronisés avec l'outil, sinon le chaos demeure.
C'est hyper fragile comme équilibre.
Très fragile.
Et il y a aussi un autre piège abordé dans l'analyse devant Gortedge.
Lequel ?
Un truc qui n'a rien à voir avec le code informatique, mais avec le texte lui-même.
Ah, les descriptions, oui.
Le drame des descriptions fournies par les fabricants.
C'est un grand classique, ça aussi.
Il faut s'imaginer, un commerçant reçoit un catalogue de produits d'une marque.
Ouais.
Et pour gagner du temps, ce qui est humain, il copie-colle la description officielle fournie par le constructeur.
Sur le papier, c'est logique.
C'est la description du produit.
Sauf que si 200 revendeurs font le même copier-coller pour vendre le même objet...
On se retrouve avec 200 pages identiques réparties sur toute Internet.
Exactement.
Et dans cette bataille du copier-coller, c'est la loi du plus fort qui s'applique toujours.
C'est-à-dire ?
L'analyve mentionne des données de l'outil AFS.
OK.
Elle montre que, face à un texte dupliqué sur plusieurs domaines, le moteur de recherche va privilégier le site qui a le plus d'autorité historique.
Le plus gros site, quoi ?
Amazon.
Ou même face au site officiel du fabricant.
Donc ça sert à rien de rivaliser sur le même texte.
C'est peine perdue.
C'est une des raisons majeures pour lesquelles certaines fiches produits sur des petites boutiques ne décollent jamais.
Alors concrètement, ça veut dire quoi tout ça ?
Eh bien...
Parce qu'on vient de voir que des centaines de milliers de doublons se créent tout seuls ?
Oui.
À cause des filtres, de l'architecture des plateformes ou des textes repris à l'identique ?
C'est un sacré bazar, on est d'accord.
Comment un moteur de recherche fait-il pour démêler ce sac de nœuds au final ?
L'auteur de l'article révèle que pour élire la bonne adresse Web, le système utilise environ 40 signaux différents.
Attends, 40 ?
40 signaux !
40 signaux, oui.
Oui, c'est un véritable faisceau d'indices.
C'est énorme !
L'algorithme ne regarde jamais un seul paramètre de manière isolée.
Il croise les données en permanence pour s'assurer qu'on ne lui ment pas.
Mais attends, il y a un truc qui m'échappe là.
Dis-moi.
Si je suis propriétaire d'une boutique...
Oui.
Et que je place la fameuse balise canonique pour dire officiellement, ceci est ma page principale.
C'est ce qu'on fait tous.
Pourquoi le moteur de recherche utiliserait 39 autres signaux derrière ?
Je veux dire, c'est mon site, c'est moi qui décide, non ?
Pourquoi ignorer mon ordre direct ?
C'est la réaction la plus naturelle.
Et pendant des années, les géants de sites ont cru que cette balise était un ordre militaire.
Bah oui, c'est logique.
Mais la réalité technique est bien différente.
Historiquement, cette balise a été tellement mal utilisée...
Avec des erreurs, tu veux dire ?
Avec tellement d'erreurs de configuration que Google a fini par la rétrograder au rang de simple indice.
Un indice ?
Juste un indice ?
C'est ça, un hint en anglais.
S'il en dise pointe vers la gauche, mais que les 39 autres signaux pointent vers la droite, le moteur de recherche l'ignore purement et simplement.
Il va à droite.
Donc en fait, c'est une suggestion polie.
Rien de plus, on suggère une adresse.
Si on remet ça dans un contexte plus global, l'ampleur du désastre technique est effarante.
L'analyse cite une autre donnée, SEMrush.
Sur les sites européens qui ont été audités, 43% présentent une erreur majeure liée à cette balise canonique.
43% ?
Près de la moitié ?
Et le pire, ce n'est pas l'absence de balise.
C'est quoi le pire ?
C'est que dans près de la moitié des cas d'erreur, la balise désigne la mauvaise adresse.
Ah non ?
Si.
Le site ordonne activement au robot d'aller dans un mur.
Donc le site ment au robot ?
Sans le faire exprès, oui.
On comprend mieux pourquoi l'algorithme a besoin de ces 40 signaux pour recouper l'information.
Il n'a plus confiance.
C'est fou.
Et parmi ces 40 signaux, l'analyse de Vanguard Edge en isole 4. 4 qui dominent largement les débats apparemment.
Ce sont les piliers, oui.
Le premier de la liste, le plus massif selon eux, c'est le maillage interne.
Le maillage interne, c'est la structure même de la boutique en fait.
Les liens entre les pages.
Voilà.
Ça agit comme un puissant système de vote.
Ok, un vote.
Chaque lien dans le menu, chaque suggestion du type « vous aimerez aussi », chaque fil d'Ariane, ça transfère du poids vers une adresse web.
C'est logique.
La version de la page qui reçoit le plus de liens internes gagne l'élection, tout simplement.
C'est pour ça que la faille de Shopify, avec l'histoire des adresses longues qu'on évoquait tout à l'heure, est si pénalisante.
Exactement.
Elle force le système de vote à élire la mauvaise page en permanence.
C'est du sabotage électoral carrément.
On peut voir ça comme ça, ouais.
Le deuxième signal ultra puissant, ce sont les redirections définitives.
Tu sais, les fameuses 301.
Oui, les 301.
Elles fonctionnent comme un panneau de déménagement.
Mais pourquoi l'article insiste-t-il autant là-dessus, notamment après une refonte de site ?
Qu'est-ce qui se passe pendant une refonte ?
Parce que les refontes laissent souvent des fantômes.
Des fantômes ?
Ouais.
Souvent, quand on refait un site, la page d'accueil et les catégories principales sont très bien redirigées.
On fait attention.
Oui, le gros du trafic.
Mais les milliers d'anciennes pages de filtre ou les anciens tris par prix qui n'existent plus dans le nouveau design… On les oublie.
On les oublie totalement.
Et ces vieilles adresses continuent de traîner dans l'index du moteur.
Ah, la catastrophe.
Ça crée un brouillard technique qui vient diluer l'autorité des nouvelles pages.
C'est pour ça qu'il faut nettoyer méticuleusement ces anciens chemins.
Ce qui nous amène au troisième signal majeur.
Le sitemap XML.
Le fameux plan du site.
C'est ça.
On fait souvent l'erreur de le voir comme un simple annuaire automatique, tu sais, où on jette toutes les pages en vrac.
C'est l'erreur numéro un.
Alors que c'est censé être beaucoup plus stratégique que ça.
Mais complètement.
Ce n'est pas un annuaire, c'est un plan d'architecte certifié.
D'accord.
Un plan qu'on remet officiellement au moteur de recherche.
Pour lui montrer la maison.
C'est ça.
Si on donne à un inspecteur un plan de bâtiment qui inclut des pièces imaginaires, des couloirs qui n'existent pas ou des placards à balais étiquetés comme des halls d'entrée.
L'inspecteur va péter un câble.
Surtout, il perd toute confiance dans le plan.
Oui, il le jette à la poubelle.
C'est pareil ici.
Si le sitemap contient des adresses web qui sont générées par des simples tris de couleurs.
Les fameux filtres de tout à l'heure.
Voilà, on détruit la crédibilité du document aux yeux des robots.
Donc le plan doit être chirurgical, rien que de l'officiel.
Chirurgical, exactement.
Et enfin, le quatrième signal.
C'est la substance même de la page, non ?
Le contenu.
Le contenu, oui.
Face à deux pages qui sont presque des jumelles, l'algorithme va toujours récompenser celles qui offrent la description la plus riche, les meilleures images ou la date de mise à jour la plus récente.
Il cherche la qualité au bout du compte.
C'est ça.
Cela soulève une question importante du coup.
Laquelle ?
Face à cette complexité technique, face à ces plateformes qui s'en mêlent, les pinceaux toutes seules.
Oui, on fait quoi ?
Comment réagir ?
Comment corriger ces contradictions de signaux sans avoir besoin de recoder toute sa boutique de A à Z ?
C'est tout l'intérêt de la méthode qui est proposée par Samy Kride dans l'article de Vanguard Edge.
La fameuse méthode.
Il détaille un plan d'action de 30 minutes, une sorte d'audit d'urgence en trois étapes.
C'est super concret, tu vas voir.
Crue.
Les pièces imaginaires.
Exactement.
S'il y a la moindre trace d'une adresse de filtre ou d'une variante de produit, on la supprime direct.
La règle est très simple.
Zéro filtre dans le plan officiel.
C'est radical, mais c'est vital.
Et la deuxième étape, c'est un test d'alignement.
Comment on fait ça ?
On sélectionne un échantillon de 5 à 10 pages qui sont vitales pour le chiffre d'affaires.
Genre la page d'accueil ou les top ventes.
Exactement.
Et on compare l'adresse qui est indiquée par la balise canonique dans le code.
L'indice donc.
L'indice.
Et on le compare avec l'adresse inscrite dans le plan du site.
Ça doit correspondre au caractère prêt.
D'accord.
Si ce n'est pas le cas, on vient d'identifier la première rupture de signal.
Le premier mensonge au robot.
C'est ça.
Et la troisième étape permet de vérifier la mécanique interne.
On utilise un logiciel d'analyse comme Screaming Frog, par exemple.
Très bon outil, oui.
Pour scanner le site en mentier.
Le but, c'est de s'assurer que quand un visiteur ou un robot navigue dans les menus, les liens sur lesquels il clique pointent bien vers la version officielle de la page.
Et non vers des variantes bizarres.
Et non vers des variantes.
C'est essentiel.
Et à l'issue de cette audite rapide de 30 minutes, des actions précises s'imposent selon l'outil qu'on utilise.
C'est là qu'on répare.
Voilà.
Pour revenir à Shopify, l'action corrective vitale, c'est de supprimer cette fameuse variable de code.
Le Within Collection.
Voilà, dans les modèles de conception.
Pour forcer les liens internes à pointer vers les adresses courtes.
Fini les adresses à rallonge.
Et il faut également configurer une non-indexation stricte sur les pages de filtres.
On leur ferme la porte.
Sur WooCommerce, tout repose sur un paramétrage vraiment millimétré du plugin de référencement.
L'objectif, c'est de garantir l'émission de signaux clairs.
Sans se contredire.
La philosophie qui est défendue par Vanguard Hedge dans tout ça, c'est ce qu'ils appellent le Search Engine Whispering.
Le murmure à l'oreille des moteurs de recherche.
J'adore l'expression.
C'est poétique.
L'idée, ce n'est pas de hurler des ordres qu'ils n'écouteront pas, comme avec la balise canonique, mais d'orchestrer le parcours en douceur.
Pour que la machine comprenne d'elle-même le chemin à suivre.
Franchement, le gain de temps et par conséquent de chiffre d'affaires justifie largement cette petite demi-heure de vérification quand on gère une boutique.
Ah bah, c'est le meilleur investissement en temps possible.
D'ailleurs, pour ceux qui souhaitent appliquer cette méthodologie pas à pas sur leur propre plateforme, l'auteur a partagé le mode d'emploi détaillé.
Avec toutes les étapes techniques.
L'URL exact pour retrouver tout ça, c'est edlion.jfalbanabogougou.com slash vanguardedgeconsulting.com slash blog urls dupliqué google seo e-commerce.
C'est un exercice de cohérence indispensable, vraiment.
L'alignement des signaux, c'est ce qui permet de transformer une boutique invisible en une mécanique d'acquisition hyper fluide.
C'est clair.
Et après avoir décortiqué tout ça, il y a une dernière réflexion qui s'impose.
Dis-moi.
On vient de voir que la simple architecture de base de nos boutiques en ligne, tu sais, ces solutions qu'on nous vend clés en main et prêtes à l'emploi.
Ouais, qui sont censées être parfaites.
Elles passent en fait leur temps à générer des contradictions internes qui détruisent discrètement notre trafic.
Sans faire de bruit.
La vraie question devient alors quels autres paramètres, par défaut totalement invisibles et silencieux, sont en train de saboter les fondations de nos vitrines numériques en ce moment même?
Ah ça, c'est une excellente question.
A méditer la prochaine fois qu'on se contente des fameux réglages d'usine.
Comment auditer les URLs dupliquées e-commerce en 30 minutes
Durée : 30 min- 1
Crawler les pages avec Screaming Frog
Lancez un crawl Screaming Frog en mode list sur vos 50 pages principales. Identifiez les URLs de filtres, tags et variantes avec paramètres qui ne devraient pas être indexées.
- 2
Vérifier la cohérence des canonicals
Sur 5 à 10 pages stratégiques (accueil, catégories principales, best-sellers), comparez la balise canonical dans le code source avec l'URL présente dans le sitemap XML. Toute divergence est une contradiction envoyée à Google.
- 3
Auditer les facettes et paramètres d'URL
Identifiez les combinaisons de filtres qui génèrent des URLs uniques. Sur Shopify, vérifiez que vos templates Liquid n'utilisent pas within: collection. Sur WooCommerce, contrôlez que les plugins de filtres ne sont pas indexables par défaut.
- 4
Corriger les liens internes incohérents
Alignez le maillage interne (menu, breadcrumbs, liens fiches produit) avec les canonicals et le sitemap. Les liens internes sont le signal le plus fort pour Google : ils doivent tous pointer vers la même URL que le canonical.
Questions fréquentes
Google pénalise-t-il le contenu dupliqué en e-commerce ?
Non, il n'existe aucune pénalité manuelle ni algorithmique pour le contenu dupliqué. John Mueller l'a reconfirmé en avril 2026. En revanche, Google choisit une URL canonique parmi les doublons et ignore les autres, ce qui dilue vos signaux SEO (backlinks, engagement) et gaspille votre budget de crawl. Un site e-commerce de 85 000 pages a perdu environ 50 000 $ par mois à cause de nouveaux produits non indexés pendant 3 à 4 semaines.
Comment vérifier si mes balises canonical sont correctes ?
Comparez trois sources sur vos 5 à 10 pages stratégiques : la balise canonical dans le code source, l'URL présente dans le sitemap XML, et les URLs de destination de votre maillage interne (menu, breadcrumbs, liens produit). Si ces trois signaux ne pointent pas vers la même URL, vous envoyez des signaux contradictoires à Google. 43 % des sites e-commerce européens ont des erreurs de canonical selon Semrush.
Les filtres à facettes créent-ils du contenu dupliqué ?
Oui, c'est le premier générateur de doublons en e-commerce. 52 % des sites e-commerce ont des problèmes liés à leur navigation à facettes selon DeepCrawl. Google a documenté un cas extrême : 158 produits ayant engendré 380 000 URLs via les combinaisons de filtres (taille, couleur, prix, marque). La solution consiste à bloquer l'indexation des pages de filtres via noindex ou robots.txt, tout en gardant les pages de catégories principales indexables.