Quand j’audite une boutique Shopify ou WooCommerce, le scénario se répète : le site est propre, les pages catégories sont travaillées, le maillage tient la route. Mais le flux produit Merchant Center ? Configuré une fois à la mise en ligne, jamais retouché depuis. Titres auto-générés, GTINs absents, catégorisation par défaut.
Le problème, c’est que ce flux est devenu le socle technique sur lequel reposent les grilles produit organiques, les AI Overviews et les agents d’achat IA. Une étude GrowByData de février 2026 montre que les Popular Products apparaissent dans 81% des SERPs e-commerce desktop aux US. Kevin Indig, dans Growth Memo, documente une augmentation de 82% des placements en grilles produit entre mai 2025 et février 2026. Le flux n’est plus un sujet Google Ads. C’est une infrastructure SEO centrale.
Les grilles produit ont pris le contrôle des SERPs e-commerce
Les chiffres convergent, quelle que soit la source. Selon les analyses croisées de Growth Memo, Brodie Clark et GrowByData, les grilles produit (Popular Products, Shopping carousels, product panels) occupent entre 81% et 96% des pages de résultats sur les requêtes e-commerce. Ce n’est plus un format émergent. C’est le format dominant.
Le cas Back Market. D’après les données Growth Memo, le site capte 59% des apparitions en grilles visuelles produit sur ses catégories principales, alors qu’il ne détient que 1,7% des positions top 3 en résultats textuels classiques. Autrement dit : Back Market a construit sa visibilité organique quasi exclusivement via les grilles, pas via le SEO “traditionnel”. Le flux produit est le canal, pas un complément.
Un autre chiffre mérite attention : selon Advanced Web Ranking (cité par Growth Memo), les grilles produit réduisent le CTR des résultats organiques classiques d’environ 50%. Si votre stratégie SEO e-commerce repose uniquement sur les positions textuelles et ignore les grilles, vous perdez la moitié du terrain. Et la donnée Growth Memo sur les pages catégories enfonce le clou : 97% des apparitions en grilles proviennent de pages catégories, contre 3% de pages produit individuelles.
Pour les boutiques que j’accompagne, la conséquence est directe. Les pages catégories doivent être pensées comme des pages d’entrée pour les grilles, avec un flux produit qui alimente ces résultats en données riches. Le SEO e-commerce a ses spécificités, et celle-ci est probablement la plus sous-estimée du moment.

Pourquoi le flux produit est devenu une infrastructure SEO
Pendant longtemps, le flux produit était un export CSV qu’on envoyait au Merchant Center pour alimenter des campagnes Shopping payantes. L’équipe SEO ne le regardait pas. C’était le problème du trafficker Google Ads.
Ça a changé pour deux raisons.
La première : Google a ouvert les grilles produit au trafic organique. Merchant Center Next permet aux marchands d’apparaître dans les grilles sans dépenser un centime en publicité. Le flux est le point d’entrée. Pas le balisage Schema seul, pas la page produit seule : le flux.
La seconde raison est plus récente et plus structurante. Le protocole UCP (Universal Commerce Protocol) de Google et l’Agent Commerce Protocol d’OpenAI utilisent tous les deux les données du flux Merchant Center comme source d’information pour leurs agents IA. Un agent qui cherche “veste imperméable homme légère moins de 100 euros” va interroger les attributs du flux. Si vos attributs sont incomplets ou approximatifs, votre produit n’existe pas pour cet agent. J’ai détaillé les implications du commerce agentique et du protocole UCP dans un article dédié.
La documentation OpenAI précise que l’Agent Commerce Protocol accepte des mises à jour de flux toutes les 15 minutes et exige TLS 1.2 minimum pour les connexions. Google, de son côté, enrichit le protocole UCP avec de nouveaux attributs : “réponses aux questions produit” et “accessoires compatibles”. Le flux n’est plus un fichier statique. C’est une API vivante que plusieurs systèmes interrogent en temps réel.
Un chiffre donne la mesure de l’enjeu commercial : selon les données agrégées seo.ai et nventory, la valeur moyenne d’une session organic shopping est de 5,38 dollars, contre 1,78 dollars pour une session organic search classique. Un ratio de 3 pour 1. Le trafic qui passe par les grilles produit convertit mieux et dépense plus. Ignorer ce canal, c’est laisser le trafic le plus rentable à vos concurrents.
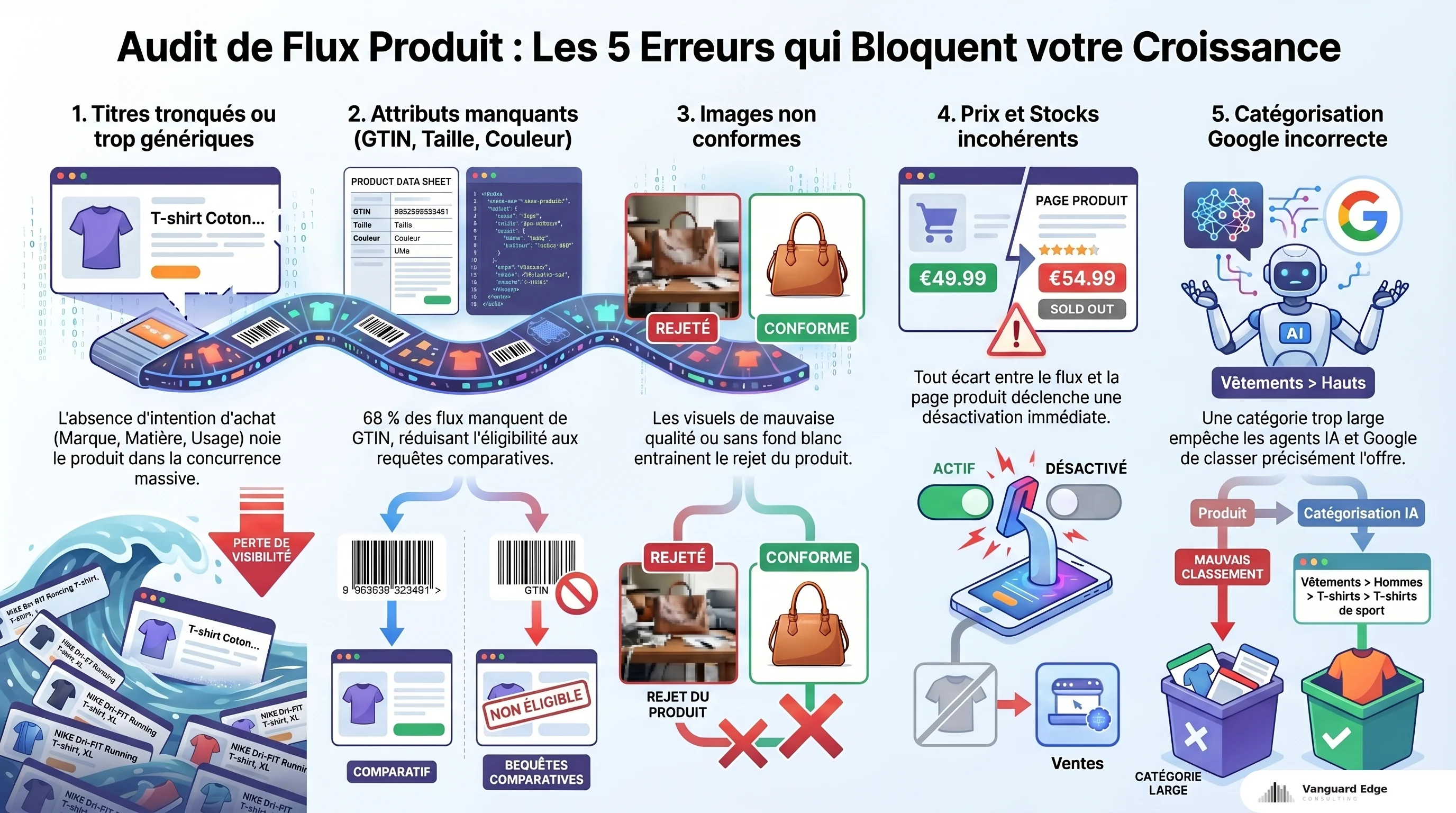
Les erreurs de flux que je retrouve en audit
Sur 40+ boutiques auditées, les problèmes de flux suivent un schéma prévisible. Et le plus fréquent est aussi le plus simple à corriger.
GTINs manquants : le problème numéro un
Selon GrowByData, 68% des flux produit analysés présentent des GTINs (Global Trade Item Number) manquants ou incorrects. C’est le défaut le plus répandu, et ses conséquences sont mesurables : les produits avec GTINs corrects génèrent en moyenne 20% de clics supplémentaires par rapport aux produits sans identifiant (données Search Engine Journal + GrowByData).
Google utilise les GTINs pour identifier un produit de façon univoque et le comparer entre marchands. Sans GTIN, le produit perd en éligibilité sur les requêtes comparatives, celles où l’utilisateur cherche un modèle précis et compare les prix. Pour les boutiques en marque propre sans GTIN, le MPN (Manufacturer Part Number) et la marque doivent être renseignés au minimum. Sans aucun identifiant, Google traite le produit comme un article non identifié.
Titres auto-générés sans intention de recherche
Shopify génère les titres du flux à partir du nom de produit dans le back-office. “Veste Homme Noire M”. C’est ce que le marchand a saisi pour gérer son inventaire, pas ce que l’acheteur tape dans Google.
Un titre de flux travaillé ressemble à : “[Marque] Veste de Running Imperméable Homme - Noir, Coque Légère, Taille M”. Les modificateurs (usage, matière, couleur, taille) correspondent aux requêtes longue traîne à forte intention d’achat. La différence entre ces deux titres, c’est la différence entre “veste homme” (concurrence massive, intention floue) et “veste running imperméable homme noire” (concurrence moindre, intention d’achat claire).
Sur les boutiques que j’accompagne, la restructuration des titres de flux fait partie des premiers leviers actionnés. C’est du travail de fond : il faut une formule par catégorie de produit, pas un template unique. Mais le ratio effort/résultat est parmi les meilleurs.
Désynchronisation prix et stock
Le flux dit 49 euros, la page produit dit 54 euros parce que le prix a changé entre deux synchronisations. Google détecte l’écart et désactive le produit. C’est un des motifs de rejet les plus fréquents dans Merchant Center.
Le même problème arrive avec le stock. Un produit marqué disponible dans le flux mais en rupture sur la page entraîne une désactivation. Sur une boutique avec 500+ références et des rotations rapides, ça peut concerner des dizaines de produits en permanence. La synchronisation en temps réel ou quasi-réel (au minimum toutes les heures) n’est pas un luxe, c’est un prérequis.
91% des flux sont sous les seuils : l’état du marché
Ce chiffre vient des données agrégées de plusieurs audits sectoriels : 91% des boutiques en ligne ont des flux produit qui ne respectent pas les seuils de qualité minimaux définis par Google. Titres trop courts, catégorisation absente ou trop large, attributs obligatoires manquants, images non conformes.
Ça veut dire deux choses. D’abord, que la concurrence réelle sur les grilles produit est bien plus faible que la concurrence sur les positions textuelles. La plupart des marchands alimentent mal leur flux, ce qui crée une opportunité pour ceux qui le font correctement. Ensuite, que les outils natifs des plateformes (les exports Shopify et WooCommerce par défaut) ne suffisent pas. Ils génèrent un flux fonctionnel, pas un flux optimisé.
Un flux optimisé, c’est un travail de cartographie : chaque catégorie de produit a sa propre formule de titre, sa taxonomie Google Product Category précise, ses attributs enrichis (matière, usage, audience cible, caractéristiques techniques). Les bottes de randonnée tactiques classées en “Chaussures > Chaussures homme” au lieu de “Vêtements et accessoires > Chaussures > Bottes > Bottes de randonnée”, c’est des signaux de pertinence perdus.

Données structurées et flux : la cohérence qui manque
Le flux produit et le balisage Schema.org sur le site sont deux représentations de la même donnée. Google les croise. Si le flux dit “49 euros” et le Schema.org sur la page dit “54 euros”, c’est un signal d’incohérence qui déclenche un rejet.
Mais le problème va au-delà de la cohérence tarifaire. Les propriétés Schema.org (offers, availability, priceValidUntil, brand, gtin) permettent aux agents IA de filtrer et comparer les produits automatiquement. Un produit avec un balisage complet et aligné avec le flux a plus de chances d’être sélectionné par un agent qu’un produit dont les données sont partielles ou contradictoires.
Je traite maintenant systématiquement la cohérence entre trois couches de données dans mes audits : les données on-page (ce que le visiteur voit), le balisage Schema (ce que le crawler lit), et le flux Merchant Center (ce que les grilles et les agents consomment). Trois représentations du même produit. Elles doivent raconter la même histoire. Les incohérences entre ces couches sont un des problèmes les plus fréquents, et aussi un des plus silencieux : le marchand ne voit pas de message d’erreur, il voit juste moins de trafic.
Agents IA : le flux comme source de vérité
Les protocoles UCP et Agent Commerce Protocol (détaillés plus haut) tirent leurs données du même endroit : le flux Merchant Center. Mais la profondeur des attributs change tout. Un flux qui renseigne matière, usage, audience cible, compatibilités et caractéristiques techniques répond aux requêtes complexes des agents, du type “veste imperméable homme légère moins de 100 euros pour trail”. Un flux avec titre, prix et image se fait éliminer dès que la requête dépasse le générique.
Et puis il y a le suivi. Comme pour le tracking GA4 en server-side, il faut savoir d’où viennent les ventes. Merchant Center fournit ses propres données de suivi : clics, impressions, conversions sur les grilles organiques. C’est une source complémentaire à Search Console, pas un substitut. Et avec la multiplication des points d’entrée (grilles, AI Overviews, agents), le suivi du parcours d’achat devient plus fragmenté. Les boutiques qui ne mesurent que le trafic organique classique passent à côté d’une partie croissante de leur acquisition.
Ce que ça change pour votre boutique
Si vous retenez un seul message de cet article : le flux produit a ses propres règles d’optimisation, ses propres métriques, et un impact direct sur le chiffre d’affaires. Le traiter comme un export technique qu’on configure une fois, c’est se couper d’un canal d’acquisition entier.
Trois priorités, dans l’ordre :
-
Auditer les GTINs et identifiants produit. C’est le levier le plus immédiat. 68% des flux ont ce problème, et le corriger améliore l’éligibilité aux grilles sans toucher au site.
-
Restructurer les titres par catégorie de produit. Pas un template générique. Une formule adaptée qui frontalise les attributs à forte intention commerciale.
-
Mettre en place une synchronisation prix/stock en temps réel et un monitoring hebdomadaire des erreurs Merchant Center, avec le même sérieux qu’un suivi Search Console.
Sur les 40+ audits e-commerce que j’ai faits cette année, le flux produit était le levier avec le meilleur ratio effort/impact dans plus de la moitié des cas. Et pourtant, c’est systématiquement le dernier sujet qu’on aborde.
Le flux produit n’est pas un chantier technique isolé. C’est la brique numéro 1 du SEO catalogue, celle qui capte 81 à 96 % des SERPs e-commerce via les grilles Shopping. Pour un e-commerçant FR qui se demande où déplacer ses euros quand il réduit son budget Google Ads, le flux produit est la première adresse. Le cadre complet d’arbitrage budgétaire : budget SEO vs Google Ads pour un Shopify français.
Vous voulez savoir si votre flux produit est à la hauteur ? Le pré-audit est gratuit : audit.vanguard-edge-consulting.com.
L'analyse en deux voix
Deux consultants discutent de ce sujet — données, cas terrain, implications business.
Lire la version texte
Bon, c'est le grand paradoxe de l'e-commerce moderne aujourd'hui.
En fait, on intervient souvent sur le terrain pour auditer des infrastructures colossales, genre des architectures Shopify Plus ou Boucommerce ultra complexe.
Et la façade est vraiment d'une propreté clinique.
Ouais, le design est généralement impeccable.
Le maillage interne est sculpté au scalpel.
Les temps de chargement sont optimisés à la milliseconde près.
On se retrouve face à des architectures qui semblent totalement invulnérables.
En fait, c'est exactement ça.
Mais ensuite, on ouvre la porte de l'arrière boutique pour vérifier un élément très précis.
Et là, c'est le chaos absolu.
Le flou produit Merchant Center, ce fameux fichier d'export, ça ressemble souvent à un terrain vague.
Ah ben, il a été configuré à la hâte le jour de la mise en production du site.
Et puis, complètement laissé à l'abandon, quoi.
Ouais, on y trouve des catégories par défaut complètement absurdes, des attributs manquants, des titres d'inventaire illisibles.
Et franchement, c'est l'angle mort massif de notre industrie.
Ouais, et l'ironie de la situation, c'est que ce fichier qui était historiquement relégué aux stagiaires ou aux gestionnaires de campagnes d'acquisition payante, il est discrètement devenu le cœur du réacteur.
Il ne s'agit plus du tout de faire du nettoyage de code XML pour satisfaire un idéal technique, tu vois.
On parle d'une infrastructure qui dicte littéralement la survie organique d'un catalogue en ligne.
C'est clair, ça impacte de front le chiffre d'affaires, la rentabilité des sessions et même la capacité d'un marchand à simplement exister dans les nouveaux écosystèmes de recherche.
Tout à fait.
Décortiquons un peu tout ça, car l'objectif de notre exploration aujourd'hui, c'est d'analyser cette bascule tectonique, comment un simple fichier de flux technique est passé d'un statut d'outil secondaire pour Google Ads à celui d'infrastructure centrale et absolue du SEO e-commerce.
Et pour comprendre cette trajectoire, il faut vraiment d'abord analyser la mutation féroce de la ligne de front, c'est à dire l'interface même des moteurs de recherche.
Les bons vieux liens bleus textuels.
Voilà, toute l'industrie a bâti ses stratégies dessus depuis 20 ans.
Mais aujourd'hui, ils sont tout simplement en train de se faire cannibaliser.
Totalement.
En fait, les données récentes illustrent une transformation radicale de l'interface utilisateur.
J'ai regardé les études croisées de Grottememo et Grobydata ou même les relevés de Brody Clark et ça montre que les gris produits, les fameux carousels visuels, c'est ça, ces immenses blocs de popular products ou produits populaires, ça domine aujourd'hui entre 81% et 96% des pages de résultats e-commerce sur ordinateur.
Et ce chiffre grimpe encore sur mobile.
Ce qui est fascinant ici, c'est que la compétition s'est déplacée.
C'est plus une simple fonctionnalité pour enrichir la page.
C'est devenu l'expérience de recherche par défaut.
Oui, plus de 80% des résultats, c'est énorme.
Ça veut dire que l'espace physique accordé au texte classique est vraiment réduit à peau de chagrin.
Ah ben, on le voit sur le terrain.
L'apparition de ces grilles visuelles amputent le taux de clic des résultats organiques classiques d'environ 50%.
C'est violent.
La moitié du trafic s'évapore instantanément parce que l'œil noyau est irrémédiablement attiré par l'image, le prix barré, les petites étoiles.
La tension est totalement suffonée.
D'ailleurs, l'exemple de Back Market est un cas d'école fascinant sur ce point.
Leur stratégie d'acquisition organique est un modèle du genre.
Sur leur catégorie phare, les données montrent que Back Market s'accapare 59% des apparitions dans ces fameuses grilles visuelles.
Ouais, ils monopolisent complètement l'espace graphique.
Exactement.
Mais la statistique la plus révélatrice, c'est leur performance sur le SI au textuel classique pour ces mêmes requêtes.
T'as une idée du chiffre ?
Je sais qu'il est bas, mais à quel point ?
Ils ne détiennent que 1,7% des positions du top 3. 1,7% ?
Ah ouais, la vache.
Ouais.
Ils ont volontairement déserté la guerre d'usure des liens bleus pour concentrer toute leur puissance de feu sur l'intégration des grilles visuelles.
Et le détail technique majeur là-dedans, c'est que 97% de ces apparitions en grille sont alimentées par les données de leur page catégorie et non pas par des fiches produits isolés.
C'est incroyable.
Mais c'est pas un pari extrêmement risqué, ça ?
Abandonner la bataille du SI au textuel classique pour tout miser sur des blocs visuels, on se met à la merci d'une mise à jour de Google du jour au lendemain, non ?
Si Google décide de réduire la taille des grilles, Backmarket perd son monopole.
Le vrai risque, ce serait de s'accrocher à un format en déclin, en fait.
La transition vers des interfaces visuelles, c'est pas un test temporaire de Google, c'est une vraie adaptation au comportement d'achat.
Le pari de Backmarket s'appuie sur une compréhension super profonde de l'intention de l'utilisateur.
C'est pas faux.
Quand quelqu'un cherche un smartphone reconditionné, il veut pas lire un bloc de texte de mille mots optimisé pour les moteurs de recherche ?
C'est clair.
Il veut voir le modèle, l'état de la batterie, la garantie, le prix, tout ça immédiatement.
Voilà.
S'entêter à optimiser le texte, c'est lutter contre la nature même de la requête.
Tu sais, c'est l'analogie que j'utilise souvent, en fait.
C'est comme s'acharner à peindre et repeindre la plus belle enseigne en bois pour sa petite boutique dans une ruelle sombre, en espérant attirer le client juste grâce au texte de l'enseigne.
Très bon image, ouais.
Pendant ce temps-là, tous les acheteurs sont agglutinés devant l'immense vitrine lumineuse et interactive de l'avenue principale juste à côté.
Si on ignore cette vitrine, les fameuses grilles produits, on perd littéralement la moitié de la rue.
On se bat pour des miettes de trafic, quoi.
Cette métaphore illustre parfaitement le problème d'allocation des ressources aujourd'hui.
L'immense majorité des équipes marketing continuent d'investir massivement dans le polissage de leurs fameuses enseignes en bois, alors que la clé d'accès à cette vitrine lumineuse, c'est ni le contenu rédactionnel, ni l'autorité du domaine, de manière classique.
C'est la qualité et la structuration du flux produit.
Exactement.
Mais du coup, si backmarket rafle 59% de ses visibilités visuelles, ça pose une question d'accès évidente.
Historiquement, Merchant Center, c'était un environnement strictement pay-to-play.
Oui, il fallait brancher Google Ads.
C'est ça, il fallait connecter la carte bleue pour y figurer.
Alors, comment ils ont fait pour pirater cette visibilité de façon purement organique ?
La mutation technologique s'est opérée avec le déploiement de Merchant Center Next.
L'écosystème s'est complètement ouvert.
Il permet désormais d'apparaître dans ses grilles gratuitement, sans aucun investissement publicitaire.
Ah, c'est un canal d'acquisition organique massif qui a été débloqué, en fait.
Oui, totalement.
Mais attention, cette ouverture n'est que la première étape d'une révolution beaucoup plus profonde.
Le flux produit est devenu la seule source de vérité lisible pour les nouveaux agents d'achat basés sur l'intelligence artificielle.
Oh là, les agents IA.
On les annonce partout comme les remplaçants des moteurs de recherche traditionnels.
Mais techniquement parlant, comment ils interagissent avec ces catalogues données ?
Un agent IA comme celui d'OpenAI, il ne va pas simplement crôler le code HTML d'une page catégorie Shopify comme le ferait le vieux Googlebot si.
Non, pas du tout.
Le scrapping classique de pages web, c'est beaucoup trop incertain pour une IA qui doit prendre des décisions d'achat ou formuler des recommandations fiables.
Les LLMs, les grands modèles de langage, ils ont une propension naturelle à halluciner, tu vois.
Oui, c'est vrai.
S'ils tentent de deviner un prix ou un stock en analysant la structure visuelle, ça peut vite partir en vrille.
Le risque d'erreur est immense.
C'est pour ça que ces géants technologiques ont développé des protocoles de communication directs.
Google utilise l'UCP, l'Universal Commerce Protocol, et OpenAI a mis en place l'Agent Commerce Protocol.
Donc, on ne parle plus du tout de SEO, au sens optimisation pour les moteurs de recherche, mais d'IEO, d'optimisation pour les intelligences artificielles, via des API dédiées.
C'est un changement de paradigme total.
Complètement.
Le flux, ce n'est plus un vieux export CSV statique mis à jour vaguement la nuit.
C'est une base de données respirante, une API vivante, soumise à des exigences drastiques.
Par exemple, la documentation d'OpenAI exige des mises à jour toutes les 15 minutes.
Attends, toutes les 15 minutes ?
Oui.
Et ce n'est pas tout.
Ils imposent un standard de sécurité cryptographique hyper sévère, comme le TLS 1.2 minimum.
TLS 1.2 ?
On rentre en des concepts de cybersécurité pure, là.
Pourquoi une IA conversationnelle exigerait un chiffrement cryptographique pour lire un simple catalogue de t-shirts ou de chaussures ?
Quel est le rapport avec la visibilité des produits ?
C'est une question de confiance absolue dans l'intégrité de la donnée.
L'Agent Commerce Protocol d'OpenAI n'est pas conçu pour juste faire du lèche-vitrine.
Il est conçu pour, à terme, exécuter des transactions à la place de l'utilisateur.
Ah ouais, carrément, acheter à notre place ?
Voilà.
Donc, si l'API n'est pas sécurisée par des protocoles cryptographiques stricts, le pipeline de données est super vulnérable aux attaques de type data poisoning.
Le fameux empoisonnement des données ?
C'est ça.
Un acteur malveillant pourrait intercepter le flux et modifier les prix ou les caractéristiques techniques avant que l'IA ne les ingère.
Sans TLS 1.2, OpenAI refuse catégoriquement d'établir la connexion.
Le marchand est tout bonnement rayé de la carte pour l'IA.
Et c'est là que ça devient vraiment intéressant.
Car au-delà de la sécurité, il y a la structuration de la donnée elle-même.
Google, via son protocole UCP, devient extrêmement pointilleux.
Il ne se contente plus du triptyque classique titre-image-prix.
Ah non, fini ça.
Il exige des attributs en profondeur, genre la compatibilité des accessoires ou des réponses préformatées aux questions fréquentes.
Si je cherche veste imperméable homme légère moins de 100 euros et que ces attributs hypergranulaires ne sont pas balisés dans le flux du marchand, est-ce que l'IA va faire l'effort de déduire que la veste est légère en analysant la description marketing du site ?
Absolument pas.
L'agent IA ne déduit rien de ce qui n'est pas formellement structuré.
Si la donnée légère ou imperméable manque dans l'architecture du flux, le produit n'existe pas dans le contexte de cette requête.
Point barre.
C'est fou.
Le système recommandera instantanément le produit du concurrent qui, lui, a fait l'effort de cartographier ses attributs.
C'est une logique d'exclusion binaire.
L'effort technique demandé est colossal, mais la récompense financière est au rendez-vous.
C'est peut-être le chiffre le plus marquant de cette analyse.
L'impact de ces nouvelles habitudes de recherche orientées flux et gris est complètement mesurable.
Oh que oui !
Une session organique typée shopping génère en moyenne 5,38 $ de valeur.
Si on compare ça à une session issue d'une recherche organique classique sur un lien textuel, ça génère seulement 1,78 $.
C'est un ratio énorme.
C'est un ratio de 1 pour 3.
Le trafic issu du flux est trois fois plus rentable.
Comment tu expliques un tel écart ?
Cet écart phénoménal s'explique par la psychologie même de l'utilisateur.
Le lien textuel correspond très souvent à une phase exploratoire.
L'internaute cherche de l'information, compare des concepts, lit des avis.
C'est du haut tunnel.
La grille produit, en revanche, intercepte l'utilisateur au bas de l'entonnoir de conversion.
L'image de l'article, son prix exact et sa disponibilité agissent comme un déclencheur transactionnel immédiat.
Un clic sur ce format indique que la décision d'achat est imminente.
Oui, c'est logique.
Mais quand on voit un tel impact financier, le décalage avec la réalité du terrain est carrément sidérant.
On pourrait croire que les e-commerçants déploient des équipes entières pour chouchouter ces flux.
Et pourtant...
Et pourtant, c'est tout le contraire.
Sur la quarantaine d'audits d'infrastructures qu'on a menés ou analysés récemment, les résultats font vraiment froid dans le dos.
91% des flux examinés n'atteignent même pas les seuils de qualité minimaux exigés par Google AdSense.
C'est le grand paradoxe qu'on évoquait au début.
L'attention de l'industrie SEO est focalisée sur l'acquisition de backlinks ou la rédaction de cocons sémantiques interminables pendant que l'infrastructure qui génère un trafic trois fois plus rentable est laissée en friche.
La concurrence réelle sur l'optimisation des flux Merchant Center est étonnamment faible.
Bon, plongeons un peu dans l'autopsie de ces 91% d'échecs.
Quels sont les points de rupture ?
On retrouve systématiquement trois erreurs fatales lors de nos analyses sur le terrain.
La première et de loin la plus courante, c'est l'absence ou la corruption des fameux codes J-T-I-N, les codes barres.
Oui, on constate que 68% des flux analysés présentent des anomalies critiques à ce niveau.
68%.
On sait tous ce qu'est un code barre dans la vraie vie, mais techniquement parlant, pourquoi autant de marchands l'ignorent ?
Et surtout, quel est l'impact algorithmique de cette négligence ?
C'est plus qu'un simple avertissement rouge dans la console, non ?
Assez bien plus que ça.
Le J-T-I n'est pas un simple champ administratif pour faire plaisir à Google.
C'est vraiment la clé de voûte du Knowledge Graph e-commerce.
L'algorithme utilise ce code pour réaliser un clustering.
Un clustering, c'est-à-dire ?
C'est-à-dire regrouper de façon univoque des produits identiques vendus par différents marchands.
Si un marchand vend un modèle spécifique d'ordinateur portable, mais qu'il ne fournit pas le J-T-I-N, Google ne prendra pas le risque algorithmique d'associer ce produit à la fiche produit globale de cet ordinateur.
D'accord.
Et la conséquence directe de ça ?
La conséquence immédiate, c'est que le marchand est purement et simplement exclu des modules de comparaison de prix et des grilles populaires associées à ce modèle précis.
La donnée montre d'ailleurs qu'un produit doté d'un J-T-I-N valide capte 20% de clics supplémentaires, juste parce qu'il accède à ces zones de forte visibilité comparative.
20% de clics en plus, c'est un sacrifice de trafic complètement incompréhensible.
Totalement.
Et ça nous amène à la deuxième erreur fatale qui illustre parfaitement le gouffre entre les contraintes techniques de l'entrepôt et le marketing digital, les titres hors-sol.
Ah, le fameux fléau des titres autogénérés par des plateformes comme Shopify.
C'est exactement ça.
Le marchand entre son produit dans le CMS avec une pure logique de magasinier.
Il saisit un truc du genre « Veste homme noir M ».
C'est très bien pour retrouver un carton dans un rayon ou faire son inventaire.
Et Shopify, par défaut, expédie ce titre exact dans le flux Merchant Center.
Sauf que l'acheteur, devant son écran, ne formule jamais ce type de requête.
Jamais.
L'intention de recherche de l'acheteur est descriptive et hyper guidée par un besoin spécifique.
L'utilisateur va plutôt taper « Veste de running imperméable homme noir ultra légère ».
Le titre de back-office « Veste homme noir M » ne contient absolument aucun des signaux lexicaux que l'algorithme ou l'IA recherche pour faire correspondre le produit à l'intention de l'utilisateur.
Il faut impérativement séparer la gestion des stocks de l'optimisation des flux.
C'est deux métiers différents.
Comment on doit restructurer ces titres concrètement pour capter cette intention de longue traîne extrêmement qualifiée ?
La création de formules de titres conditionnelles est impérative.
Selon la taxonomie du catalogue, la structure doit varier.
Par exemple, pour du prêt-à-porter, la concaténation idéale, c'est souvent marque plus sexe plus type de produit plus attributs différenciants comme la matière ou le cas d'usage plus couleur et taille.
Donc le « Veste homme noir » devient quoi ?
Ça doit devenir un truc comme « Salomon, veste de running homme, imperméable, coque légère, noir, taille M ».
L'intégration des modificateurs comme imperméable ou coque légère injecte la donnée granulaire que l'IA recherche désespérément.
C'est ouf, parce qu'au final, c'est une simple réorganisation de chaîne de caractère qui change drastiquement la portée du produit.
Exactement.
Mais il y a un 3e point de rupture qu'on voit tout le temps sur le terrain.
Et c'est peut-être le plus redoutable, car il entraîne des sanctions invisibles et automatiques.
La désynchronisation.
Ah oui, là, anti-SBI commerçant.
On observe constamment des flux qui annoncent un produit à 49 euros, alors que la page de destination l'affiche à 54 euros à cause d'une promo qui vient d'expirer, par exemple.
J'imagine que l'afficheur sur la page web et le fichier de flux doivent correspondre, mais on oublie souvent la couche invisible, le fameux balisage schéma.org.
C'est souvent là que ça casse, non ?
Oui.
La mécanique de vérification de Google repose sur une cohérence tripartite très stricte.
Il y a le flux Merchant Center poussé par API, le rendu visuel de la page HTML et le balisage de données structurées schéma.org, enfouie dans le code source.
Et Google vérifie les 3 en même temps ?
Absolument.
Il opère des micro-crawls permanents pour comparer ces 3 sources.
S'il détecte la moindre friction, ne serait-ce qu'une différence de quelques centimes entre le json du flux et le balisage schéma mis en cache sur la page, la sanction est algorithmique et immédiate.
Le produit est rejeté.
Ah ouais, le fameux Product Disapproved qui clignote en rouge dans la console sans crier gare.
Le vrai problème, c'est ce qu'on appelle la race condition.
C'est ce décalage temporel entre la mise à jour d'un cache de page web et le ping d'une API.
Sur un catalogue qui subit des rotations de prix dynamiques ou des variations de stock intensives, cette désynchronisation peut désactiver des centaines de produits les plus rentables d'un coup.
Sans même qu'une alerte humaine ne se déclenche immédiatement.
Exactement.
Une synchronisation en temps réel via l'API couplée à un monitoring hyper agressif des rejets, c'est aujourd'hui la seule parade viable.
L'exigence technique a vraiment atteint un niveau chirurgical.
On est très loin du petit fichier qu'on bidouillait sur Excel le vendredi après-midi.
Ça, c'est sûr.
Si on devait dresser un plan de bataille immédiat pour ceux qui gèrent ces plateformes au quotidien, les actions à très haut rendement se dessinent assez clairement.
1.
Le nettoyage ultra approfondi des identifiants uniques, les fameux GTIN, pour débloquer la puissance du Knowledge Graph.
Oui, c'est la base.
2.
L'arrêt immédiat de l'export natif des titres d'inventaire qu'on remplace par des règles de réécriture conditionnelles qui ciblent vraiment les attributs de recherche.
Et 3.
Le blindage absolu de la synchronisation tripartite, on-page, schéma et flux, en temps réel.
Ce triptyque, ça constitue vraiment la base de l'infrastructure moderne.
Les entreprises qui maîtrisent ces trois piliers s'adjugent un avantage compétitif, d'autant plus puissant qu'il est purement organique et extrêmement difficile à répliquer sans une discipline technique de fer.
C'est passionnant et en même temps, ça soulève une réflexion philosophique assez vertigineuse sur l'avenir même de notre métier.
Si les agents d'achats d'OpenAI, de Google ou d'autres écosystèmes se nourrissent désormais exclusivement de ces attributs de flux structurés, ils se moquent éperdument de l'expérience utilisateur visuel.
C'est le grand paradoxe.
L'IA ne voit pas si la police de caractère est élégante ou si le bouton d'ajout au panier a la couleur parfaite pour convertir l'œil humain.
Elle ingère juste des nœuds de données cryptographiques.
Oui, et c'est là-dessus qu'il faut s'interroger.
La fonction première de l'interface visuelle va progressivement se réduire.
Je suis convaincu que la conception de City Commerce consistera de moins en moins à persuader un acheteur humain avec un design émotionnel.
Mais beaucoup plus à structurer une architecture de données hyper dense.
Exactement.
Une base de données capable de convaincre un agent robotisé de la pertinence technique d'un produit.
L'optimisation pour l'algorithme d'achat va petit à petit supplanter l'optimisation pour l'œil humain.
Voilà une perspective qui bouscule franchement toutes les certitudes de l'industrie.
Je veux dire, pourquoi investir des fortunes dans l'esthétique d'une boutique si le véritable client, l'agent IA qui fait les courses et compare les prix à la vitesse de la lumière, il ne se soucie que de la perfection d'un fichier de flux JSON bien sécurisé ?
C'est toute la question des prochaines années.
C'est sur cette observation et la bascule d'une ère du tout visuel vers une ère de la donnée structurée pure que s'achève notre analyse aujourd'hui.
L'entretien de ces infrastructures invisibles n'est définitivement plus une corvée administrative.
C'est l'essence même de la compétition moderne.
Merci de nous avoir suivis et à très vite pour une nouvelle plongée en profondeur.
Comment auditer et optimiser votre flux produit e-commerce
Durée : 30 min- 1
Auditer les GTINs et titres du flux
Exportez votre flux Merchant Center et vérifiez les GTINs manquants ou incorrects (68 % des flux sont concernés). Restructurez les titres par catégorie de produit en frontalisant marque, usage, matière et taille au lieu des titres auto-générés du back-office.
- 2
Vérifier la cohérence flux-schema-page
Croisez les données du flux avec le balisage Schema.org et le contenu visible sur chaque fiche produit. Prix, disponibilité et attributs doivent correspondre sur les trois couches. Un écart de prix entre le flux et la page entraîne une désactivation par Google.
- 3
Mettre en place un monitoring Merchant Center
Configurez une synchronisation prix et stock au minimum toutes les heures et un suivi hebdomadaire des erreurs Merchant Center. Surveillez les rejets de produits, les désactivations de stock et les alertes de catégorisation.
Questions fréquentes
Le flux produit Merchant Center impacte-t-il le SEO organique ?
Oui, directement. Le flux produit alimente les grilles produit organiques (Popular Products, Shopping carousels) qui apparaissent dans 81 % des SERPs e-commerce desktop selon GrowByData. Une session organic shopping vaut en moyenne 5,38 $ contre 1,78 $ en organic search classique. Un flux mal optimisé vous exclut de ce canal sans que Google ne vous envoie d'alerte.
Quels attributs sont obligatoires dans un flux produit e-commerce ?
Au minimum : GTIN ou MPN + marque, titre restructuré par catégorie (marque, usage, matière, taille), prix synchronisé en temps réel, disponibilité à jour, et Google Product Category précise. 68 % des flux ont des GTINs manquants ou incorrects, et les produits avec GTINs corrects génèrent en moyenne 20 % de clics supplémentaires.
Comment savoir si mon flux produit est mal optimisé ?
Exportez votre flux Merchant Center et vérifiez trois points : les GTINs manquants (68 % des flux sont concernés), les titres auto-générés identiques aux noms du back-office, et les écarts de prix ou de stock entre le flux et vos pages produit. Un taux de rejet élevé dans le Merchant Center et une absence de vos produits dans les grilles organiques sont les symptômes les plus visibles.