900 millions d’utilisateurs actifs par semaine. C’est le chiffre qu’OpenAI avance pour ChatGPT en avril 2026. Parmi eux, une part croissante tape des requêtes produit : “meilleure imprimante 3D 2026”, “crème solaire bio bébé”, “chaussures trail imperméables femme”. Et derrière chaque requête, un pipeline technique décide quels sites méritent d’être cités dans la réponse.
Sur les 12 derniers mois, les sessions e-commerce provenant de ChatGPT ont bondi de 1 079 % (Visibility Labs, 94 sites). Le chiffre est spectaculaire, mais il part de quasi-rien : une étude académique portant sur 973 sites montre que ChatGPT représente encore environ 0,2 % des sessions e-commerce, tout en captant plus de 90 % du trafic issu des LLMs (Kaiser et Schulze, 2026). C’est un canal naissant, mais c’est celui qui croît le plus vite. Et les sites qui s’y positionnent maintenant prennent de l’avance.
Ce qui suit couvre le fonctionnement interne de ChatGPT Search, les blocages techniques courants et les corrections par CMS.
Comment ChatGPT Search explore le web (architecture web.run)
ChatGPT Search ne fonctionne pas comme un moteur classique. Le modèle envoie des requêtes, récupère des pages, les lit, et synthétise une réponse. Tout ce processus passe par un outil interne nommé web.run.
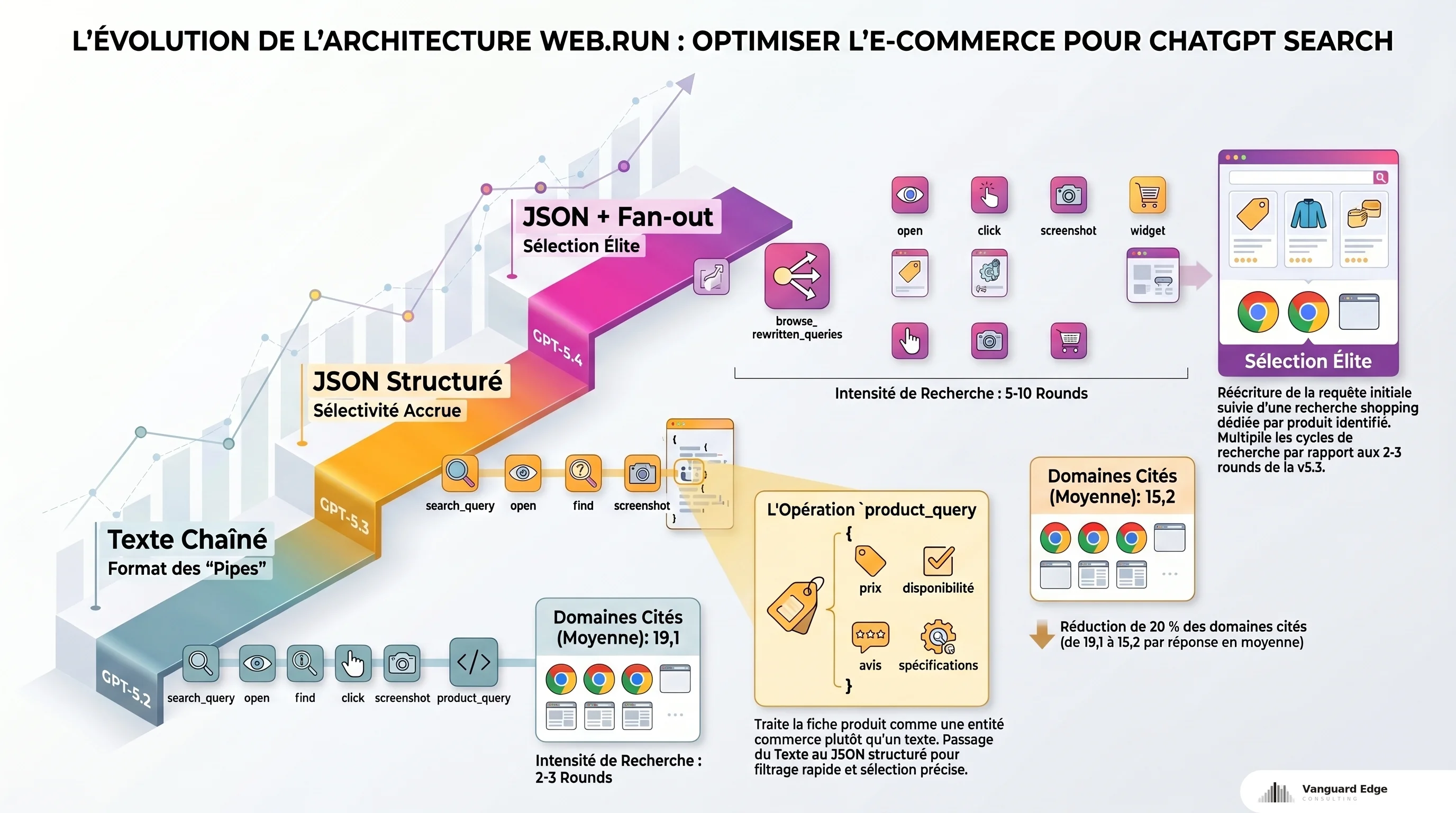
Les 12 opérations du pipeline web.run
Le monitoring de l’architecture révèle 12 opérations distinctes : search_query, open, find, click, screenshot, product_query, plus des widgets spécialisés (sport, finance, météo). Avant GPT-5.3, ces commandes passaient sous forme de texte chaîné (des “pipes”). Depuis, le format est du JSON structuré.
Conséquence directe : le modèle est plus précis dans ses requêtes, mais aussi plus sélectif. Le JSON structuré permet à GPT-5.3 de filtrer plus vite et de citer moins de sources. Sur 14 semaines de monitoring (400 prompts/jour), le passage de GPT-5.2 à GPT-5.3 Instant a réduit de 20 % le nombre de domaines cités par réponse (de 19,1 à 15,2 en moyenne). Moins de places, plus de concurrence.
Pour un e-commerçant, le point clé est product_query. Cette opération cible les requêtes produit et déclenche un traitement différent des requêtes informationnelles. Votre fiche produit n’est pas évaluée comme un article de blog. Elle est traitée comme une entité commerce avec des attributs attendus : prix, disponibilité, avis, spécifications.
Fan-outs et browse_rewritten_queries : ce que ça change pour les produits
GPT-5.4 pousse la logique encore plus loin avec 5 à 10 rounds de recherche par réponse (contre 2-3 pour GPT-5.3). Mais le mécanisme le plus intéressant pour le e-commerce est browse_rewritten_queries, un fan-out non documenté apparu avec GPT-5.3 Instant et spécifique aux requêtes produit.
Prenons une requête concrète : “meilleure imprimante 3D 2026”. Le modèle exécute d’abord un fan-out de réécriture pour construire une liste de produits, puis lance un fan-out shopping par produit individuel. Il ne se contente pas de chercher une seule fois. Il reformule et segmente la requête, puis compare les résultats entre eux.
Votre fiche produit a donc plusieurs occasions d’être trouvée, mais seulement si elle est techniquement accessible et sémantiquement riche. Une page produit minimaliste (titre + prix + bouton “Ajouter au panier”) passe à travers les mailles du filet. C’est le même problème que pour les grilles produit Google qui prennent le dessus sur les résultats organiques : la richesse des données produit détermine la visibilité, quel que soit le canal.
ChatGPT-User : le crawler qui ne dort jamais
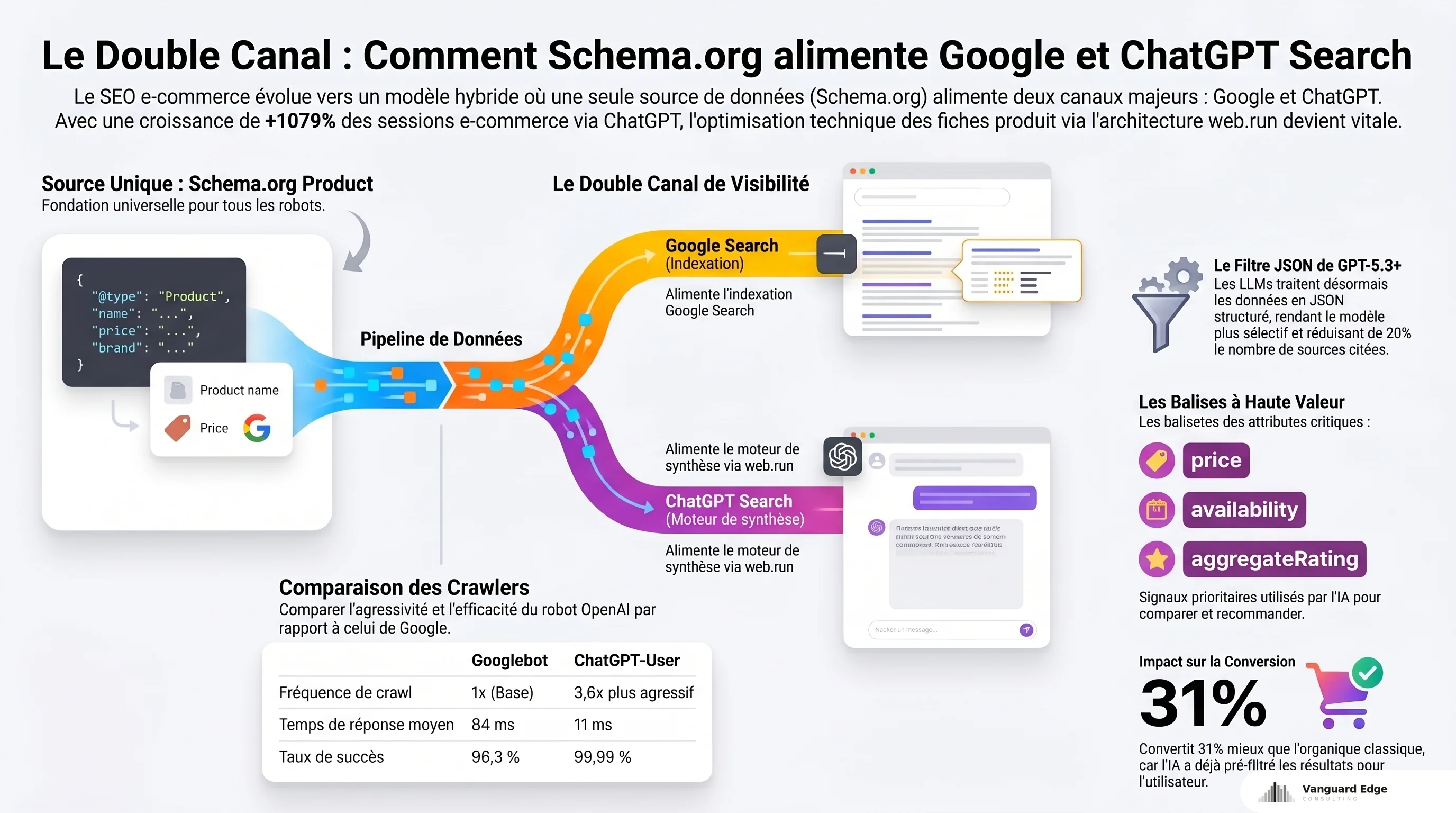
Il y a deux robots OpenAI, et la confusion entre les deux coûte de la visibilité à beaucoup de sites. OAI-SearchBot construit l’index de recherche. ChatGPT-User récupère les pages en temps réel quand un utilisateur pose une question.
Ce qui frappe dans les données de crawl, c’est l’agressivité de ChatGPT-User. Sur une analyse de 24,4 millions de requêtes couvrant 69 sites pendant 55 jours (Alli AI, Search Engine Journal), ChatGPT-User crawle 3,6 fois plus que Googlebot. Avec un taux de succès de 99,99 % et un temps de réponse moyen de 11 ms, contre 96,3 % et 84 ms pour Googlebot. Le crawler d’OpenAI est rapide et exigeant. Et il revient souvent.
Identifier ChatGPT-User dans vos logs serveur
Dans vos logs Apache ou Nginx, filtrez sur la chaîne ChatGPT-User. Ce que vous cherchez :
- Fréquence des requêtes : si vous voyez 0 hit, votre site est probablement bloqué ou invisible.
- Pages visitées : le crawler cible-t-il vos fiches produit ou seulement votre page d’accueil ?
- Codes de réponse : des 403, 429 ou 503 en masse signalent un blocage actif (WAF, rate limiting, Cloudflare en mode strict).
Un client dans les accessoires outdoor avait un taux de blocage de 78 % sur ChatGPT-User à cause d’une règle Cloudflare trop agressive sur les bots non-Google. Après correction, ses pages produit ont commencé à apparaître dans les réponses ChatGPT sous 72 heures.
Robots.txt et crawl budget IA : les erreurs fréquentes
Trois configurations que je vois régulièrement sur les boutiques Shopify et WooCommerce :
-
Un
Disallow: /pourUser-agent: *dans le robots.txt envoie un signal de blocage à ChatGPT-User. En pratique, OpenAI indique que ce crawler, agissant à la demande d’un utilisateur, ne respecte pas toujours le robots.txt. Le blocage réel passe par le WAF ou le rate limiting. Mais le signal reste négatif. -
Certains e-commerçants bloquent
GPTBot(le crawler d’entraînement, pas de recherche) et bloquent aussiChatGPT-Userpar association, sans réaliser que ce sont deux agents distincts. -
ChatGPT-User utilise le sitemap pour découvrir les URLs. Si votre sitemap n’est pas déclaré dans le robots.txt ou s’il ne contient pas vos fiches produit, le crawler ne sait pas où aller.
Un trafic faible en volume, fort en conversion
Les e-commerçants qui commencent à mesurer le trafic ChatGPT découvrent un profil inhabituel. Le volume reste marginal, mais le comportement est différent du trafic organique classique.
Le taux de conversion du trafic ChatGPT atteint 1,81 %, contre 1,39 % pour l’organique non-brandé, soit 31 % de plus (Visibility Labs, 94 sites). L’utilisateur qui arrive via ChatGPT a déjà filtré et comparé. Il est plus avancé dans sa décision d’achat.
Mais le panier moyen est 14,3 % inférieur ($204 contre $238 en organique) d’après Kaiser et Schulze. Une hypothèse : le modèle oriente vers le meilleur rapport qualité-prix plutôt que vers le premium. Pour un site positionné sur la valeur, c’est un avantage. Pour une marque premium, il faudra travailler la visibilité paramétrique pour que le modèle comprenne le positionnement prix. C’est un facteur que nous avions documenté dans notre analyse du GEO e-commerce.

Visibilité paramétrique vs dynamique : le piège des sites e-commerce
Deux types de visibilité coexistent. La paramétrique : ce que le modèle sait de votre site via son entraînement. C’est stable, lent à construire, comparable au E-E-A-T des moteurs classiques. La dynamique : ce qu’il récupère en temps réel via web.run. Volatile, rapide, plus proche du SEO technique traditionnel.
Le piège pour les sites e-commerce : ils dépendent presque entièrement de la visibilité dynamique (prix, stock, fiches produit) mais n’investissent pas dans la visibilité paramétrique (contenu éditorial, guides d’achat, pages comparatives). Le modèle ne les connaît pas assez pour les chercher en temps réel.
Reddit bénéficie d’une exemption des limites copyright, ce qui lui donne un avantage structurel. Sur des requêtes produit, les threads “best X for Y” sont souvent cités en priorité. L’enjeu est le même que pour la priorisation SEO vs GEO : choisir les pages qui méritent d’être visibles plutôt que tout indexer en espérant que ça passe.
Données structurées : le double canal que vous sous-exploitez
Google, Microsoft et OpenAI ont tous confirmé publiquement que le schema markup aide les LLMs à interpréter les pages web (BrightEdge, Search Engine Journal). ChatGPT utilise concrètement les schemas FAQPage et Article pour formuler ses réponses, et Organization pour l’attribution des sources.
Des traces Google (paramètres strlid) apparaissent dans les URLs produits récupérés par ChatGPT Search. Le backend s’appuie sur des fournisseurs de recherche tiers. Vos données structurées alimentent un double canal : Google d’abord, puis ChatGPT via Google. Un schema Product incomplet vous pénalise deux fois.
Et le modèle fait confiance aux données structurées quand elles sont cohérentes avec le contenu textuel. Un schema Product qui annonce 29,90 EUR alors que le texte visible affiche 39,90 EUR crée un signal de contradiction qui pénalise la citation.
Les balises à prioriser au-delà du minimum (name, price, availability) : brand pour désambiguïser les produits similaires, sku et gtin pour les identifiants que le modèle croise avec ses données paramétriques, aggregateRating pour la confiance, mainEntityOfPage pour signaler la source canonique. L’enjeu est le même que pour le commerce agentique et les UCP : fournir aux agents IA des données structurées complètes, pas juste le minimum.
Checklist par CMS : Shopify et WooCommerce
Shopify
Le robots.txt est partiellement géré par Shopify. Depuis 2024, vous pouvez le personnaliser via robots.txt.liquid dans votre thème. Vérifiez que ni ChatGPT-User ni GPTBot ne sont bloqués. Certaines apps de sécurité (Rewind, Locksmith) ajoutent des règles sans prévenir.
Le sitemap auto-généré inclut les produits actifs mais exclut brouillons et archivés. Le piège : les variantes ne sont pas dans le sitemap. Si vous avez un produit avec 15 variantes de couleur, seule la page principale est indexable.
Les données structurées Product sont intégrées nativement dans les thèmes récents (Dawn, Sense, Craft). Mais les champs aggregateRating, brand et sku sont souvent vides si vous ne les remplissez pas. Or ce sont les attributs que product_query exploite.
Le rendu est hybride : Shopify sert du HTML statique via Liquid, ce qui est bon. Mais les apps tierces (reviews, upsell, bundles) injectent du contenu via JS côté client. Auditez chaque app.
Au-delà du rendu HTML, Shopify a rendu cette visibilité native via ses serveurs MCP Storefront : ChatGPT et les autres agents peuvent interroger directement le catalogue sans repasser par un crawl HTML classique. C’est une couche complémentaire — pas un remplacement du schema produit.
WooCommerce
Le robots.txt est sous votre contrôle total. Vérifiez qu’il ne bloque pas les URLs /product/ et qu’il déclare votre sitemap. Les données structurées dépendent de votre plugin SEO : Rank Math gère mieux les variantes que Yoast (chaque variation a son propre schema avec prix et disponibilité).
Le rendu côté serveur dépend de votre stack. Un WooCommerce classique avec Storefront sert du HTML statique. Un WooCommerce headless avec une façade React/Next.js nécessite du SSR correctement configuré, sinon ChatGPT-User ne voit rien. Le test : désactivez JavaScript dans votre navigateur. Ce que vous voyez, c’est ce que le crawler voit.
Demain : le zero-click commerce
McKinsey estime à 1 000 milliards de dollars le shopping agentique aux US dans les cinq prochaines années (Practical Ecommerce). La direction est claire : zero-click et instant checkout. L’utilisateur décrit ce qu’il veut, l’agent compare et achète. Sans jamais visiter votre site.
Les sites e-commerce qui ne traitent pas la visibilité IA comme un canal technique à part entière vont perdre du terrain trimestre après trimestre. Les données structurées et l’accessibilité crawler ne sont plus des “nice to have”. C’est l’infrastructure de base pour exister dans une réponse générée.
Vous ne savez pas si ChatGPT Search voit vos fiches produit ? Demandez un audit de visibilité IA.
L'analyse en deux voix
Deux consultants discutent de ce sujet — données, cas terrain, implications business.
Lire la version texte
Imaginons un instant, un centre commercial gigantesque, mais vraiment un truc d'une taille tentaculaire, ouvert de jour comme de nuit, sans interruption.
Ouais, le genre d'infrastructure qui ne ferme jamais ses portes, en fait.
Exactement.
Et qui attire, on parle de la bagatelle, de 900 millions de visiteurs chaque semaine.
C'est juste dingue.
C'est l'équivalent de toute la population de l'Europe, plus une bonne partie de l'Amérique du Nord, qui se baladeraient au même temps dans les allées.
Ça donne le vertige quand on visualise la chose comme ça.
Complètement.
Sauf que dans ce fameux centre commercial, la majorité écrasante des gérants de boutiques n'ont même pas conscience que la porte d'entrée de leur propre magasin, elle est virtuellement invisible.
C'est ça le pire.
Ils sont là, mais on ne les voit pas.
Ouais, et il y a pire encore.
L'agent de sécurité qu'ils ont eux-mêmes embauché à l'entrée de la boutique passe ses journées à refouler violemment les clients les plus qualifiés et les plus riches du marché.
Bah oui, c'est une situation complètement absurde.
C'est totalement absurde.
Mais c'est exactement la réalité du commerce en ligne aujourd'hui, en ce mois d'avril 2026, avec chaque GPT.
On le sait, le modèle a franchi ce cap hallucinant des 900 millions d'utilisateurs actifs hebdomadaires.
Et le truc, c'est qu'une part grandissante de ce trafic a radicalement changé de nature.
Ouais, clairement, les gens ne viennent plus juste pour lui faire écrire un poème ou résumer une réunion Zoom interminable.
Voilà, aujourd'hui, on tape des requêtes purement transactionnelles.
Il y a une intention d'achat qui est féroce.
On voit passer des recherches ultra ciblées du genre meilleur imprimante 3D résine 2026 ou crème solaire bio bébé poids topique.
Et les données récentes illustrent ce changement de paradigme d'une violence inouïe pour le coup.
Si on regarde juste la métrique des sessions e-commerce qui viennent directement des recommandations de Tchad GPT, on observe une explosion phénoménale.
On parle de 1079% de croissance sur les douze derniers mois.
Plus de 1000%, c'est juste énorme.
Ouais, c'est énorme.
Mais après, il faut garder la tête froide et contextualiser un peu ce volume.
Au final, ça ne représente encore que 0,2% du trafic web marchand total aujourd'hui.
Donc, statistiquement, c'est une goutte d'eau, en fait.
Exactement, c'est une goutte d'eau.
Néanmoins, cette fameuse goutte d'eau, elle monopolise déjà plus de 90% de tout le trafic commercial généré par l'ensemble des grands modèles de langage sur le marché.
En termes de vélocité, c'est le canal d'acquisition client qui a la courbe de croissance la plus agressive de l'histoire du e-commerce.
Et c'est précisément pour ça qu'on fait cette analyse approfondie aujourd'hui.
L'idée ici, c'est pas de philosopher sur des concepts abstraits d'intelligence artificielle ou quoi que ce soit.
On va vraiment adopter une posture stricte de praticien du SEO e-commerce.
Ouais, on va parler à ceux qui ont les mains dans les logs serveurs depuis plus de dix ans.
Voilà, je suis persuadée que c'est là que ça se joue.
Notre objectif, c'est vraiment de décortiquer la réalité technique de l'infrastructure.
Comment ces algorithmes font pour cartographier concrètement une boutique ?
Pourquoi est-ce que de grandes marques se tirent une balle dans le pied techniquement sans s'en rendre compte ?
Et surtout, comment on doit restructurer l'architecture d'un site pour transformer ce nouveau trafic en margennette, quoi ?
L'enjeu, il est strictement financier.
Faut pas se leurrer.
Chaque friction technique dont on va parler aujourd'hui, ça se le paye cash.
C'est un coût d'acquisition client qui flambe.
C'est du chiffre d'affaires fantôme.
Et c'est surtout une hémorragie de parts de marché au profit d'acteurs plus petits, mais plus agiles.
Des acteurs qui ont déjà compris la syntaxe des machines, en fait.
C'est clair.
Et la première étape pour capter cette nouvelle vague d'acheteurs.
J'ai l'impression que ça demande de complètement désapprendre nos anciens réflexes SEO.
Ah bah totalement.
Chat GPT, ça se comporte pas du tout comme un moteur de recherche traditionnel qui va juste puiser passivement dans un index figé.
C'est pas Google, il y a dix ans, quoi.
D'accord.
Alors, essayons de comprendre ce qui se passe sous le capot, en fait.
Si l'approche est si différente d'un Googlebot classique, c'est quoi la logique de l'algorithme quand un utilisateur cherche, je sais pas, des chaussures de trail imperméables ?
Comment il décide qui mérite d'être cité ?
Le cœur du réacteur, ça repose sur un environnement d'exécution interne qui s'appelle Web.run.
Quand il détecte une intention de recherche complexe, le modèle déploie carrément des agents en temps réel sur le réseau.
Des agents qui font quoi, concrètement ?
En gros, le monitoring du site architecture montre qu'il a une douzaine d'opérations distinctes à sa disposition.
Il va utiliser la commande Search Query pour interroger le Web, Open pour ouvrir et extraire une page, Find pour isoler un bout de texte, Click pour naviguer de lien en lien ou même Screenshop pour valider visuellement un rendu.
Ah ouais, donc il interagit vraiment avec la page, il ne se contente pas de lire le code source bêtement.
Exactement.
Mais la vraie révolution, celle qui a tout bouleversé pour le e-commerce, c'est la bascule technique vers le modèle GPT 5.3.
Attends, qu'est-ce qui a changé spécifiquement avec cette version 5.3 pour que ça bouscule autant les règles d'indexation des boutiques ?
J'avoue que j'ai vu passer le truc, mais j'aimerais bien qu'on creuse.
C'est le format de traitement des données.
Avant cette version, le modèle envoyé recevait ses commandes sous forme de texte classique.
C'était fonctionnel, mais c'était assez lourd et ça créait pas mal d'erreurs d'interprétation si le code de la page était un peu brouillon.
Et donc, avec la 5.3, ils ont changé le format de lecture ?
Ouais.
L'intégralité du pipeline est passée sur du JSON.
C'est un format de données hyper structuré.
La conséquence, elle est brutale.
L'algorithme est devenu d'une précision chirurgicale, mais sa tolérance à l'imperfection a littéralement chuté à zéro.
D'accord, donc si elle a moindre erreur de syntaxe, c'est mort.
C'est exactement ça.
Un parsing strict en JSON, ça veut dire que si une balise est mal fermée, bim, la source entière est rejetée.
C'est pas comme un navigateur web classique Chrome ou Safari qui va essayer de réparer visuellement un code un peu cassé pour afficher la page quand même.
Le bot, il s'en fout, il rejette tout.
Et ça a eu un impact direct sur la visibilité des marchands, j'imagine ?
Ah bah, sur des milliers de parcours d'achat qu'on a monitorés, ce changement a provoqué une chute sèche de 20% du nombre de domaines cités dans les réponses.
En moyenne, on est passé de 19,1 domaines marchands mentionnés à seulement 15,2.
Waouh, donc du jour au lendemain, juste à cause d'une petite mise à jour de format de lecture interne, l'entonnoir s'est drastiquement resserré.
La compétition a augmenté de 20% sans qu'aucune marque n'ait touché à ces produits.
C'est fou, hein ?
Le modèle a besoin de beaucoup moins de sources pour garantir sa réponse maintenant, mais à la seule condition que ses sources aient un code JSON parfait.
Et pour le e-commerce, cette exigence de perfection, elle se cristallise autour d'une commande spécifique parmi les 12 qu'on a citées.
C'est la fonction Product Query.
La fameuse Product Query.
Ça, ça ne s'active que quand l'intention d'achat est détectée.
C'est ça, Evelyne ?
Ouais, exclusivement.
Et ça modifie totalement la façon dont l'agent va lire la page.
Qu'est-ce que ça implique pour le marchand ?
Il ne lit pas la fiche produit de la même manière qu'un tuto ou qu'un article de blog ?
Non, absolument pas.
Quand l'agent déploie une Product Query, il ne cherche plus du texte informatif pour faire une synthèse.
Il cherche à valider ce que le système appelle une entité commerce.
Donc, la fiche produit, elle est passée au scanner à travers un prisme purement transactionnel.
Et c'est hyper sévère.
C'est-à-dire ?
Il veut quoi comme info exactement ?
Il s'attend à extraire des variables quantifiables et définitives.
Il faut un prix non ambibu, une notion de stock en temps réel, un volume d'avis client avec des vrais métriques vérifiables et des spécifications techniques normées.
Ah ouais, d'accord.
Donc, la page super minimaliste, un peu vitrine de luxe avec juste un beau titre, une énorme photo lifestyle bien léchée, un prix planqué en bas et un bouton d'achat.
Ça passe plus du tout.
Ça va échouer lamentablement.
L'agent va ouvrir la page, constater qu'il n'y a aucune profondeur de données structurées et il va tout simplement l'ignorer dans sa réponse finale.
En gros, si on résume la dynamique de la version actuelle, la 5.4, moi, je me dis que l'IA se comporte vraiment comme un personal shopper, mais genre un personal shopper complètement obsessionnel.
Ouais, c'est un peu l'idée.
Au lieu de marcher dans la rue et de regarder vaguement la devanture des magasins, il établit une grille de critères strictes.
Il fait une liste de courses, puis il se démultiplie en dizaines de clones pour fouiller chaque rayon sur chaque étagère jusqu'à trouver le produit techniquement parfait.
C'est marrant que tu dis ça parce que cette métaphore du clonage méthodique, elle est très juste techniquement.
C'est exactement le processus qu'on appelle le fan out shopping.
Sous GPT 5.4, l'agent ne se limite plus à faire deux ou trois recherches simples.
Il orchestre entre cinq et dix cycles complets d'investigation en arrière plan avant même de taper un seul mot à l'écran pour l'utilisateur.
Ah oui, c'est pour ça qu'il y a un petit délai parfois avec l'icône de recherche qui tourne.
Voilà le mécanisme interne qui gère ça.
Ça s'appelle Browse Rewritten Queries.
Pour te donner un exemple concret, si l'utilisateur demande une crème solaire bio bébé, le premier cycle de recherche, il ne va même pas chercher des produits.
Attends, il cherche quoi d'abord alors?
L'agent va d'abord lancer des requêtes génériques pour cartographier le marché.
Il va vérifier les controverses dermatologiques du moment.
Il va lister les marques qui ont les bonnes certifications bio, etc.
Et une fois qu'il a ces entités en tête, là, il entame son deuxième cycle.
Le fameux fan out.
D'accord, c'est là qu'il se démultiplie.
C'est ça.
Il se clone pour lancer des recherches individuelles et simultanées sur chaque marque certifiée pour trouver les fiches produits.
Et après, il y a même un troisième cycle qui va juste consister à vérifier le prix et la disponibilité en direct sur différents sites e-commerce pour comparer.
Franchement, c'est fascinant.
Mais du coup, si ce robot mène des enquêtes aussi profondes sur autant de niveaux juste pour une seule requête utilisateur, j'imagine qu'il doit marteler les serveurs des sites d'une façon hyper brutale.
C'est ça qui nous amène à notre histoire de blocage massif.
Notre agent de sécurité qui repousse les clients à l'entrée.
Mais t'as mille voix dessus.
C'est le cœur du problème.
T'as beau avoir la fiche produit la plus optimisée du monde, le code Jison le plus parfait.
Si l'agent IA se fait teige par les couches de sécurité du serveur, ton produit n'existe pas pour lui.
C'est un drame financier silencieux.
En fait, il y a plein de marchands qui s'en rendent même pas compte.
Complètement silencieux.
Et la confusion, elle vient d'une méconnaissance globale de l'écosystème d'OpenAI parce qu'OpenAI, ils ont deux agents distincts qui font des choses diamétralement opposées.
Le premier, c'est OAI Searchbot.
Lui, c'est un robot d'indexation classique comme le Googlebot.
Il navigue doucement.
Il prend son temps pour alimenter les bases de données froides du modèle.
Mais il y a le second, le fameux ChatGPT User, le Personal Shopper qui agit en direct.
Exactement.
Lui, c'est le crawler temps réel et il ne s'active qu'à la fraction de seconde où l'utilisateur clique sur envoyer.
La pression technique est colossale.
Si tu regardes les analyses de logs, tu vois que cet agent explore les sites 3,6 fois plus agressivement qu'un bot d'indexation classique.
3,6 fois plus.
Mais c'est perçu comme une attaque des DOS par les serveurs, ça non ?
Bah ouais, d'autant plus que la fenêtre de tir est critique.
Pour que l'utilisateur ait l'impression d'avoir une discussion fluide avec l'IA, l'agent technique a un temps de réponse exigé de l'ordre de 11 millisecondes par requête.
11 millisecondes ?
Mais attends, techniquement, c'est une contrainte complètement délirante pour un site e-commerce standard.
Franchement, un Googlebot traditionnel, ça tourne souvent autour de 80 ou 90 millisecondes de tolérance et ça demande déjà d'être bien optimisé.
Je sais, c'est ultra agressif.
Si on prend un site qui tourne avec une base de données un peu lourde, genre un Magento ou un WooCommerce avec 15 plugins pour gérer les promos, les déclinaisons de couleurs, le serveur, il lui faut plusieurs centaines de millisecondes juste pour se réveiller et générer la page HTML.
À moins d'utiliser du cache ultra agressif en périphérie, ce qu'on appelle l'edge computing.
Et c'est là que les pare-feux s'affolent.
Tu m'étonnes.
On a eu un cas très parlant avec un client, un grand fabricant d'équipements outdoor de haute montagne.
Du jour au lendemain, il s'étonnait d'avoir totalement disparu des recommandations conversationnelles de ChatGPT.
On a fait un audit de leur load server et on a vu que 78% du trafic qui venait de ChatGPT user finissait dans un mur.
78% de rejet.
Ah ouais.
Et c'était dû à quoi ?
C'était leur pare-feux applicatif.
Leur WAF chez Cloudflare était configuré pour filtrer automatiquement toute activité frénétique qui n'avait pas l'empreinte IP officielle d'un moteur de recherche historique genre Google ou Bing.
Donc à l'échelle de cette boîte internationale, on parle potentiellement de millions d'euros de manque à gagner juste parce que le pare-feu a pris ce personnage shopper ultra pressé pour une attaque de bottes malveillants.
Ouais, des millions.
C'est dramatique.
Mais alors, je veux me faire l'avocat du diable une seconde.
Le pillage de contenus à grande échelle, le scrapping industriel qu'on voit partout pour entraîner des modèles concurrents sans payer les auteurs, c'est un vrai problème, non ?
Face à ça, est-ce que ce n'est pas une décision business super rationnelle de juste fermer les vannes au niveau du pare-feu ?
Alors oui, protéger sa propriété intellectuelle contre l'entraînement des modèles, c'est vital et légitime.
Mais là où la rationalité s'effondre, c'est quand on confond les acteurs.
Bloquer l'extraction massive à froid, OK.
Mais refouler chaque GPT user, c'est une erreur stratégique fondamentale.
Parce qu'il n'entraîne pas le modèle, lui.
Exactement.
Ce robot n'aspire pas les données pour le deep learning.
Il agit comme le mandataire direct d'un acheteur qui vienne taper une intention d'achat explicite.
Le bloquer, comme je dis souvent, c'est littéralement barricader la porte d'un magasin pendant les soldes.
Et le pire, c'est que l'analyse technique montre que c'est rarement intentionnel de la part des marques.
C'est de l'ignorance technique.
Il y a des erreurs systémiques récurrentes, j'imagine.
On en voit trois tout le temps, surtout sur les grands CMS.
La première, hyper basique.
Le fameux DSolo slash générique dans le fichier robots.txt.
Le mec veut bloquer l'IA.
Il met une règle globale.
Sauf que le chat GPT user, vu qu'il est mandaté par un humain qui fait une requête en direct, techniquement, il pourrait forcer le passage, non ?
Il pourrait forcer le passage, oui.
Mais la présence de cette ligne dans le robot.txt, ça envoie un signal d'interdiction qui va souvent déclencher un blocage dur par le serveur hébergeur en cascade.
C'est bête.
Et la deuxième erreur, si je suis ta logique sur la confusion des identités, c'est quand l'administrateur système interdit l'accès au GPT bot, qui est l'aspirateur d'entraînement.
Mais par excès de zèle, il met aussi le chat GPT user sur la liste noire.
C'est classique.
Une ligne de code mal ciblée sera par feu et pouf, tout le canal de vent s'évapore.
Et puis, tu as la troisième erreur systémique, qui est super intéressante, parce qu'elle touche à la topographie du site et au sitemap XML.
Ah, le fameux plan du site.
Qu'est-ce qui cloche avec le sitemap ?
Ben, souviens-toi de la contrainte des 11 millisecondes.
L'agent, il a tellement pas le temps de naviguer qu'il se fie aveuglément au sitemap pour localiser les produits.
Mais sur des plateformes comme Shopify, par exemple, le système natif te génère un sitemap avec l'URL principale du produit, mais ça exclut de base les URL des variantes.
Ah mince !
Donc si je vends un sac à dos technique avec 12 couleurs différentes, les 11 autres couleurs, elles sont virtuellement invisibles pour le bot ?
Complètement invisibles.
Le modèle IA pourra jamais répondre à une requête ultra spécifique du genre sac à dos trail rouge, parce que pour lui, l'URL n'existe pas.
Et il y a un autre truc lié à l'architecture très courant sur les sites headless avec WooCommerce.
C'est quand tu sépares la base de données de l'interface visuelle avec du React ou du Vue.js, c'est ça ?
Ouais.
Si le rendu côté serveur, le server side rendering, il a une micro défaillance temporelle, l'agent IA ne va pas attendre que le JavaScript s'exécute sur le navigateur.
Il lira juste un écran vide.
D'ailleurs, le crash test est simple.
Tu désactives le JavaScript de ton navigateur, tu recharges ta fiche produit.
Si ton prix ou ton bouton panier disparaît, ton produit n'existe pas dans l'économie conversationnelle.
C'est un test impitoyable, franchement.
Bon, du coup, franchissons encore une étape.
Admettons que l'infrastructure réseau tienne le choc des 11 millisecondes, que le pare-feu laisse entrer le robot et que le sitemap soit nickel.
L'agent accède enfin à la fiche produit.
On dit que je veux qu'il analyse ça avec sa product query hyper strict.
Mais comment l'algorithme évalue que cette part est légitime au point de la recommander à l'acheteur final ?
J'ai lu des rapports de Locke qui montraient la présence de paramètres de suivi bizarres, des strict leads dans les URL de ChatGPT.
C'est quoi le lien avec Google là-dedans ?
C'est une excellente question et ça touche à un système à double canal absolument crucial pour la conversion.
En fait, le moteur de recherche de ChatGPT, il ne bosse pas tout seul.
Il s'appuie massivement sur des API externes en arrière-plan et particulièrement sur l'index de Google.
Les paramètres strict leads qu'on voit dans les logs, c'est la preuve technique que la requête passe par Google.
Donc, si je comprends bien, la compréhension sémantique de l'IA, elle est d'abord filtrée parce que Google a compris du site.
Exactement.
Et quel est le langage universel qui permet à Google et à l'IA de transformer une page web visuelle en une base de données lisible ?
Ce sont les données structurées.
Le balisage Schema.And.
Le Schema Product ?
Le Schema Product, oui.
C'est le nerf de la guerre.
S'il est incomplet, l'effet punitif, il est double.
Tu perds des positions sur Google classique et tu te prives à 100% du tremplin vers les générateurs d'IA.
Et j'imagine que la machine ne fait preuve d'absolument aucune clémence sur les erreurs de balisage.
Surtout que le modèle accorde une confiance aveugle à ce code invisible.
Mais il faut que ça matche parfaitement avec ce qu'il y a à l'écran, non ?
Par exemple, si j'ai un script promo JavaScript qui affiche le prix à 59 euros sur la page, mais que mon balisage Schema, en fond, il est resté bloqué à 79 euros ?
Oh là là, ça c'est fatal.
C'est ce qu'on appelle la pénalité de contradiction fatale.
Il faut bien comprendre un truc.
Les modèles de langage comme GPT, ils sont terrifiés à l'idée de générer des hallucinations ou de mentir à l'utilisateur.
C'est leur pire cauchemar au niveau de l'alignement.
Ah ouais ?
Donc, s'il y a une contradiction entre le code et le visuel...
Bim !
L'indice de confiance de la source est détruit instantanément.
La fiche produit est éradiquée de la synthèse.
Pour sécuriser sa position, il faut blinder son balisage au-delà du classique titre, prix, dispo.
Il y a 4 balises Schema qui sont devenues une question de vie ou de mort pour l'e-commerce.
D'accord.
Alors, si on veut vraiment blinder sa page techniquement, aujourd'hui, c'est quoi ces 4 variables entouchables ?
Alors, premièrement, l'attribut brand, la marque.
C'est essentiel pour que l'IA puisse désambiguiser des termes génériques dans un marché saturé.
Deuxièmement, le SKU, donc ton identifiant interne de gestion de stock.
Et troisièmement, et ça c'est souvent le gros maillon faible, c'est le code barre international, le Gettin.
C'est l'élément pivot.
Attends, pourquoi un simple code barre industriel, genre EAN13, ça a autant de poids pour un modèle linguistique ?
Ce code barre, c'est la connexion directe entre la collecte de données en temps réel, qu'il fait sur ta page, et les milliards de paramètres figés dans son réseau de neurones lors de son long entraînement statique.
Ah !
Donc quand il voit le Gettin, il relie ta page à tout ce qu'il a déjà ingéré sur ce produit depuis des années.
Mais tout à fait.
Quand l'algorithme trouve un Gettin certifié, il n'a plus besoin d'analyser ton texte en doutant.
Il relie instantanément ton offre à toute la base de connaissances mondiale qu'il a sur ce produit exact.
Ça fait exploser le score de pertinence.
Et enfin, la quatrième variable, c'est l'aggregate rating, donc la note globale des avis clients.
C'est la validation sociale quantifiée que la machine exige avant de recommander.
C'est fou l'impact de cette ingénierie technique sur la rentabilité pure en fait.
Surtout quand on regarde les données comportementales derrière.
J'ai vu des études sectorielles qui montraient que l'acheteur qui clique sur un lien sourcé par JTPC, il a un profil complètement hors norme.
Le taux de conversion sur ce trafic-là s'établit à 1,81% en moyenne contre 1,39% pour le trafic organique classique.
C'est un bond de 31% !
C'est farmineux !
C'est énorme !
Mais psychologiquement, ça s'explique hyper bien en fait.
L'internaute qui clique sur la recommandation de l'IA, il a littéralement sous-traité toute la friction de l'achat à la machine.
L'analyse des specs, la comparaison, la lecture de centaines d'avis clients, l'IA a déjà tout filtré.
Donc au moment où la page de ton site s'ouvre, la décision d'achat dans la tête du gars est déjà prise.
Oui mais attention, ce taux de conversion stratosphérique, il cache une réalité financière qui est beaucoup plus nuancée pour les marchands.
Ah oui ?
Qu'est-ce qui cloche ?
Cette hyper-rationalisation a un effet collatéral majeur.
On observe une chute mécanique de 14,3% du panier moyen.
Globalement, sur le panel étudié, le panier passe de 238 dollars en organique classique à environ 204 dollars via l'IA.
Et ça s'explique comment cette baisse ?
L'IA cherche toujours le moins cher ?
C'est la nature même de l'algorithme.
L'intelligence artificielle, c'est un acheteur qui n'a absolument aucune impulsion émotionnelle.
Elle s'en fiche complètement de l'esthétique luxueuse de ton interface, de ton storytelling ou de tes pop-up de cross-selling.
Son seul et unique objectif, c'est l'optimisation mathématique du rapport qualité-prix en fonction de la requête de base.
Ah ouais, je vois.
Donc pour un gros acteur du mass-market ou un site de discount qui joue sur les volumes et les prix cassés, ce trafic IA, c'est du pain béni.
C'est hyper rentable.
C'est une mine d'or pour eux.
Mais par contre, pour une marque premium ou genre un artisan qui vend des produits à haute valeur ajoutée, c'est une catastrophe.
L'IA va mécaniquement les pénaliser parce qu'elle voit juste un produit plus cher avec les mêmes specs bruts.
Comment ces marques font pour s'en sortir ?
C'est l'enjeu crucial de la décennie pour ces marques-là.
Ça nous amène à la distinction entre la visibilité dynamique et la visibilité paramétrique.
C'est-à-dire ?
Aujourd'hui, la majorité des sites e-commerce sont obsédés par la visibilité dynamique, c'est-à-dire l'instant T.
Avoir le prix à jour, le stock vert, la date de livraison bien affichée, c'est super.
Mais pour l'IA, c'est totalement insuffisant.
L'IA a besoin de contexte et c'est là que les critères EEAT de Google entrent en jeu.
Expérience, expertise, autorité et fiabilité.
D'accord, donc l'historique et la confiance.
Exactement.
Pour qu'un modèle IA recommande un article premium beaucoup plus cher, il faut qu'il ait ingéré, pendant son entraînement de plusieurs mois, une masse d'informations textuelles qui justifie ce surcoût.
C'est ça la visibilité paramétrique.
Donc si je vends un sac en cuir artisanal magnifique à 600 euros, mais que j'ai juste une page produit classique avec mon prix dynamique, l'IA va comparer mes dimensions et mon type de cuir avec un sac industriel à 60 balles et elle va me rejeter direct pour non-compétitivité.
Voilà, t'as tout compris.
La machine ne comprend pas l'artisanat si tu ne lui expliques pas avec des données.
Faut nourrir la machine en amont alors.
Il faut publier des guides d'achat massifs, des vrais manifestes sur la provenance du cuir, des comparatifs hyper poussés.
D'ailleurs, c'est sûrement ça qui explique l'avantage concurrentiel hallucinant qu'on décide comme Reddit en ce moment.
Les IA s'abreuvent de ces milliers de débats humains, de retours d'expériences super pointus pour forger leur définition de l'expertise et de l'autorité.
C'est exactement ça.
En synthèse, le message pour les décideurs du e-commerce, il est sans appel.
Aujourd'hui, le SEO technique de papa limité aux balises HTML, H1, H2, c'est terminé.
Ça a fusionné avec les exigences hyper strictes des grands modèles de langage.
C'est devenu de l'ingénierie serveur en fait.
Ouais.
Intégrer un schéma JSON parfait, surveiller ses logs serveurs tous les jours, garantir un temps de réponse sous les 15 millisecondes à la périphérie du réseau, c'est plus de l'optimisation de confort.
C'est devenu l'infrastructure de survie pour n'importe quel boîtier commerce à l'ère de l'IA.
Surtout quand on lève les yeux vers l'avenir très, très proche.
J'ai lu une projection vertigineuse de McKinsey l'autre jour.
Ils anticipent que ce qu'ils appellent le shopping agentique, ça va représenter un volume de plus de 1000 milliards de dollars juste aux États-Unis d'ici 5 ans.
Ah oui, le shopping agentique, c'est l'avènement du zéro clic commerce.
C'est fou comme concept.
L'acte d'achat sans aucune navigation.
L'utilisateur dicte juste son besoin à l'oral, à son téléphone.
Et bam, l'agent IA lance ses requêtes internes web.run.
Il scanne les entités avec Product Query.
Il vérifie le balisage JSON.
Et vu qu'il a les droits sur le portefeuille numérique de l'utilisateur, il valide carrément le paiement en arrière plan.
La transaction se fait de bout en bout sans que l'humain n'ait jamais vu l'interface graphique du site marchand.
Les marques qui n'auront pas structuré leur base de données pour ce robot vont tout simplement s'évaporer.
Ce qui soulève une question finale hyper intéressante qui touche presque à la philosophie ou à la sociologie.
Si l'avenir, c'est ça, des milliers d'agents logiciels invisibles qui comparent des données JSON et valident des paiements en 11 millisecondes.
Que va-t-il rester de la sérendipité ?
Du plaisir de la découverte par hasard ?
De l'achat d'impulsion un peu déraisonnable ?
C'est la grande inconnue.
Franchement, quel sera le poids d'un design de site magnifique ?
D'une photo d'ambiance travaillée pendant des heures ?
Ou même de l'attachement affectif à une marque ?
Si la porte d'entrée de ce fameux centre commercial géant dont on parlait au début, elle n'est franchie que par des bouts de codes mathématiques qui s'arrêtent jamais pour contempler les vitrines, quelle est la valeur réelle d'une belle vitrine aujourd'hui ?
Je pense que la redéfinition de l'espace marchand, elle ne fait vraiment que commencer.
Et franchement, ça va être radical.
Comment vérifier que ChatGPT Search voit votre site e-commerce
Durée : 20 min- 1
Analyser les logs serveur
Filtrez vos logs Apache ou Nginx sur la chaîne ChatGPT-User. Vérifiez la fréquence des requêtes, les pages visitées et les codes de réponse. Zéro hit signifie que votre site est bloqué ou invisible.
- 2
Auditer le robots.txt
Vérifiez que ni ChatGPT-User ni GPTBot ne sont bloqués par erreur. Assurez-vous que votre sitemap est déclaré et qu'il contient bien vos fiches produit.
- 3
Valider les données structurées
Contrôlez la présence et la cohérence des schemas Product, FAQPage et Organization sur vos pages clés. Un prix différent entre le schema et le texte visible crée un signal de contradiction qui pénalise la citation.
- 4
Tester en navigation privée
Ouvrez ChatGPT en navigation privée et tapez vos requêtes produit cibles. Notez si vos pages apparaissent dans les sources citées. Répétez le test après chaque correction pour mesurer l'impact.
Questions fréquentes
Quelle différence entre les crawlers ChatGPT-User et OAI-SearchBot ?
OAI-SearchBot construit l'index de recherche d'OpenAI, comme Googlebot pour Google. ChatGPT-User, lui, récupère les pages en temps réel quand un utilisateur pose une question. Sur 24,4 millions de requêtes analysées, ChatGPT-User crawle 3,6 fois plus que Googlebot avec un taux de succès de 99,99 %. Bloquer l'un sans le vouloir en ciblant l'autre est une erreur fréquente qui coûte de la visibilité.
Les données structurées aident-elles à apparaître dans ChatGPT Search ?
Oui. Google, Microsoft et OpenAI ont confirmé que le schema markup aide les LLMs à interpréter les pages web. ChatGPT utilise concrètement les schemas FAQPage et Article pour formuler ses réponses, et Organization pour l'attribution des sources. Un schema Product incomplet pénalise doublement : côté Google d'abord, puis côté ChatGPT qui s'appuie sur les résultats Google.
Le trafic ChatGPT convertit-il mieux que le trafic organique classique ?
Le taux de conversion du trafic ChatGPT atteint 1,81 % contre 1,39 % pour l'organique non-brandé, soit 31 % de plus selon Visibility Labs sur 94 sites. En revanche, le panier moyen est 14,3 % inférieur (204 $ contre 238 $). Le visiteur ChatGPT a déjà comparé et filtré ses options avant de cliquer, ce qui explique un taux de conversion supérieur sur des produits à prix moyen.